Introduction:
Automated Machine Learning (Auto ML) in Power BI is a powerful feature that is designed to automate the process of machine learning and allows users to successfully transform tasks like data imputation, feature engineering, model selection, training, testing and visualizing their results.
Microsoft has introduced this incredibly smart feature to enable people with relatively little or no knowledge of Machine Learning. Auto ML is not only time-efficient, it also gets quality results in a reasonable amount of time for its users.
- Please note that this feature is only available in Premium Capacity as of now.
It is important to understand that this feature, regardless of how innovative and efficient it is, does not replace all the machine learning techniques out there. In fact, there are many custom applications that cannot be applied to this feature. Therefore, it is important to keep in mind the specific functionalities of Auto ML.
Note: It is recommended that you acquaint yourself with basic machine learning concepts and understand the differences between ML models to ensure better accuracy when and if you want to optimize a model later.
Scope: We will be demonstrating how to apply Auto ML using Power BI in this blog. A second blog will feature the breakdown of the model report containing model training and accuracy details along with the instruction on how we can apply the trained model on a dataset.
Problem: Airbnb is an online marketplace for arranging/offering lodging, homestays, or tourism experiences. Let’s say we want to predict the price of the places (apartments, houses etc.) listed on Airbnb using historical data. We have opted for a demo dataset from github. We want to predict the price based on a few columns (features in ML terms) e.g. the number of bedrooms, the number of bathrooms, does it come with a swimming pool or not etc.
Implementation:
- Go to Power BI Service and navigate to your desired workspace.
- In your workspace, click on +Create -> Dataflow
- Click on Add entities
- You can choose from a lot of options. In the current scenario, we’ll be using a CSV
- Click on the Next
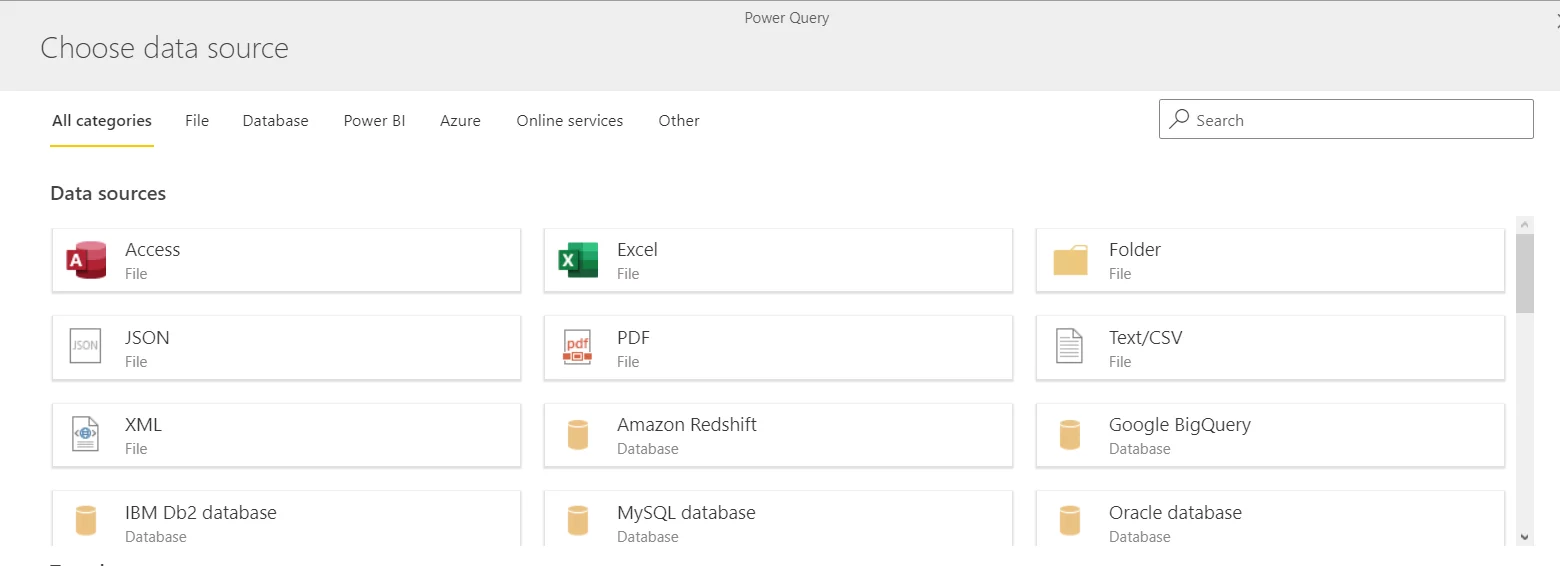
- Paste the URL if the file exists on the web or OData feed
- If there is an on-premises dataset you want to use, you will have to configure the On-premises data gateway field and provide authentication for it.
- Click on the Next button
- Click on the Next button
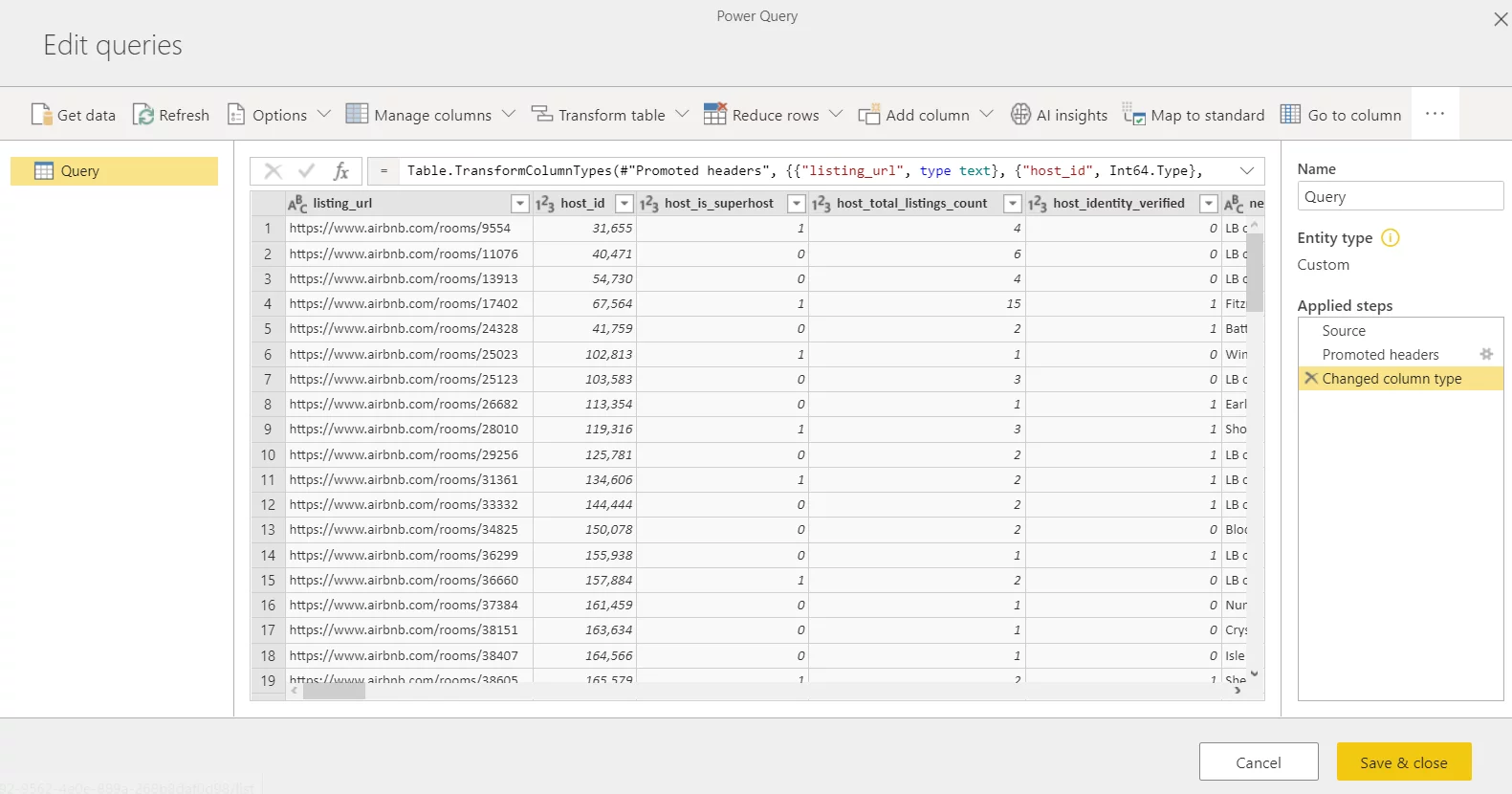
- A new Power Query window will open. It will automatically promote headers and change the column types of some fields.
- Rename the query.
- Click on Save & close
You can perform data type changes if you want to. In this demonstration, we will not interfere with the data, we will simply demonstrate the results that Auto ML produces.
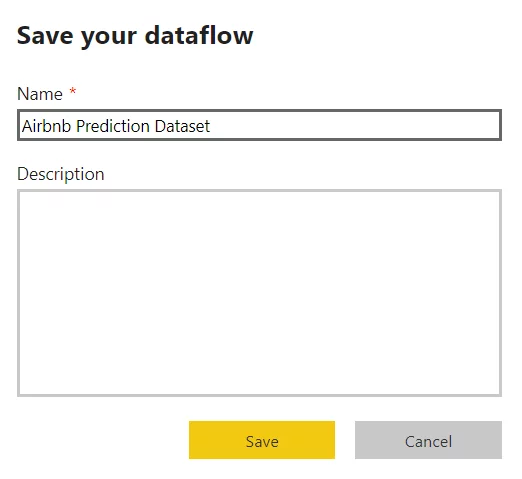
- Provide a name for your dataflow and click Save
- Open the saved entity by clicking on it
- In Actions, click on Apply ML Model (circled in screenshot)
- A small tab will display Add a Machine Learning Model option, click on it

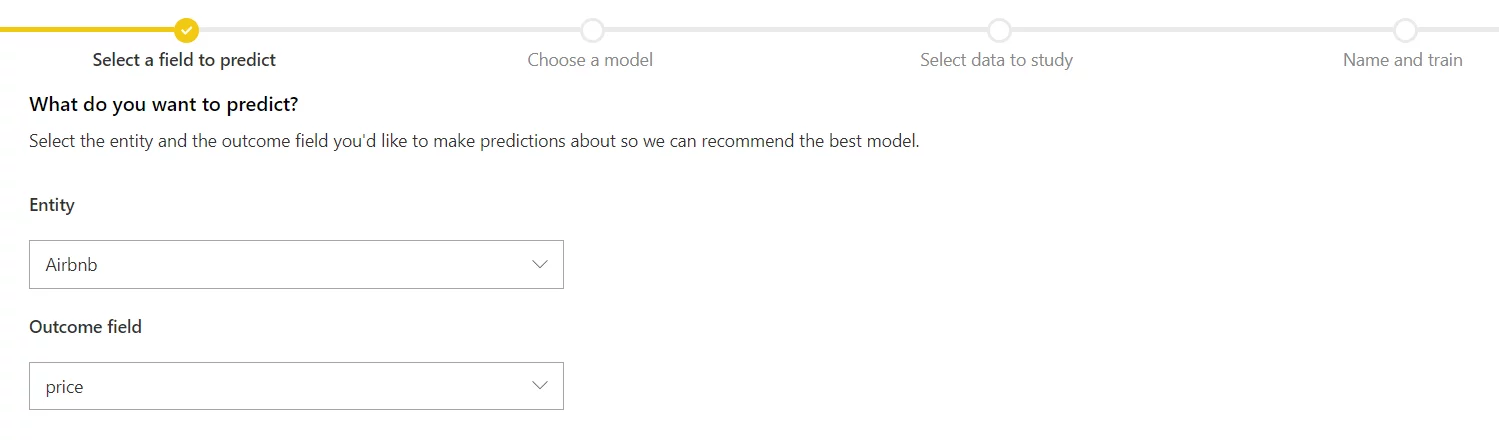
Specifying the outcome field:
- Select Outcome field. It is the field we want to predict, in this case, it is the price of the Airbnb.
- Click on Next.
Model Selection:
In the next window, it will automatically suggest a Regression Model based on the outcome field. You can manually select a different model, if your dataset requires one. In our case, it has suggested the correct model.
We will not be going into the details about the differences in the models provided by Microsoft in Auto ML. However, Auto ML’s documentation provides you with everything you need to know about the supported ML models.
- Click on Next.
In the next window, the system has automatically suggested a Regression Model based on the outcome field. You can manually select a different model if you’re sure your dataset requires one. In the current case, it has suggested the correct model.
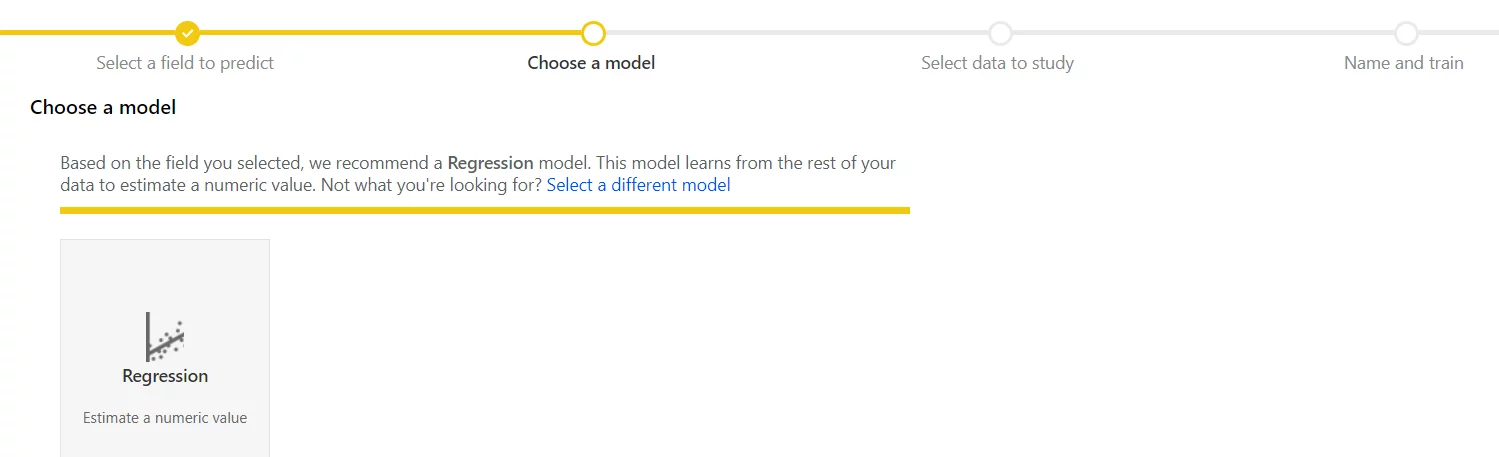
- Click on Next.
Feature Selection:
Now, this is smart! Auto ML calculates correlation between available columns and the outcome field. It calculates, to what degree the outcome field is subject to change based on another field. As shown in the image below, it does not select fields with low correlation or fields having too many distinct values (e.g. unique identifiers/ID columns). It only selects fields which it thinks have significant correlation with the outcome field.
The purpose of this process is to only select meaningful features/columns and to reach accurate results in a reasonable amount of time. In Machine Learning terms, it’s called Feature Engineering or Feature Selection.
We will continue with the suggested selection.

Adjust Training Time:
In the final step, you can adjust Training Time. It depends on the use case, if you want to see the insights quickly, you can select relatively smaller training time. But on the other hand, if you want to generate more accurate results you may need to give ample training time to the model. You can always re-train your model if you think it’s not good enough.
In the Training Details depicted below details, it says 80% of the sample data will be used in training and the other 20% will be used for model testing. In ML terms, this is called Train-Test Split.
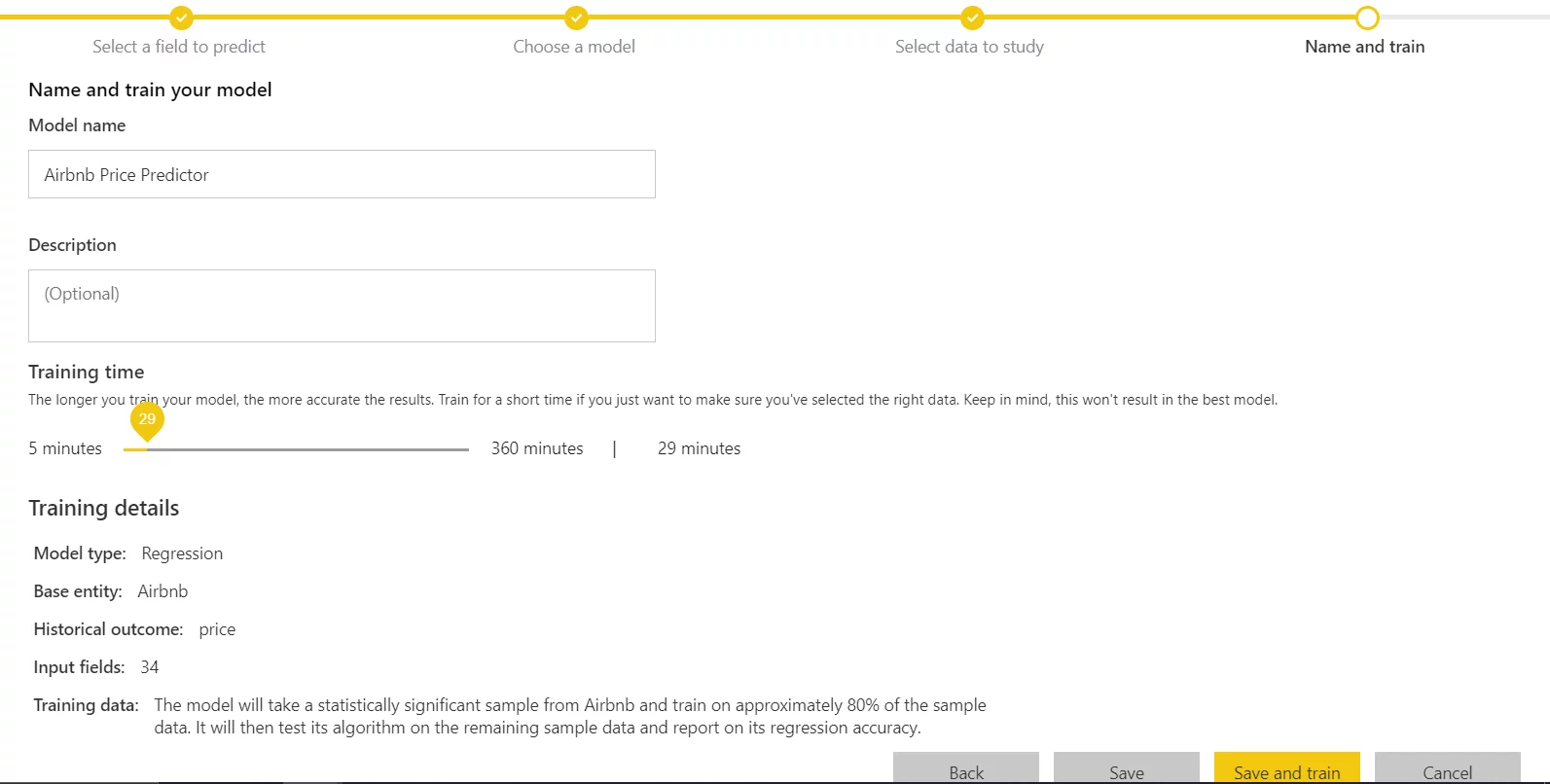
- Click on Save and train. The model will start training.
You will be directed to the Dataflows tab in the workspace. You will see the refresh symbol in front of the Dataflow.
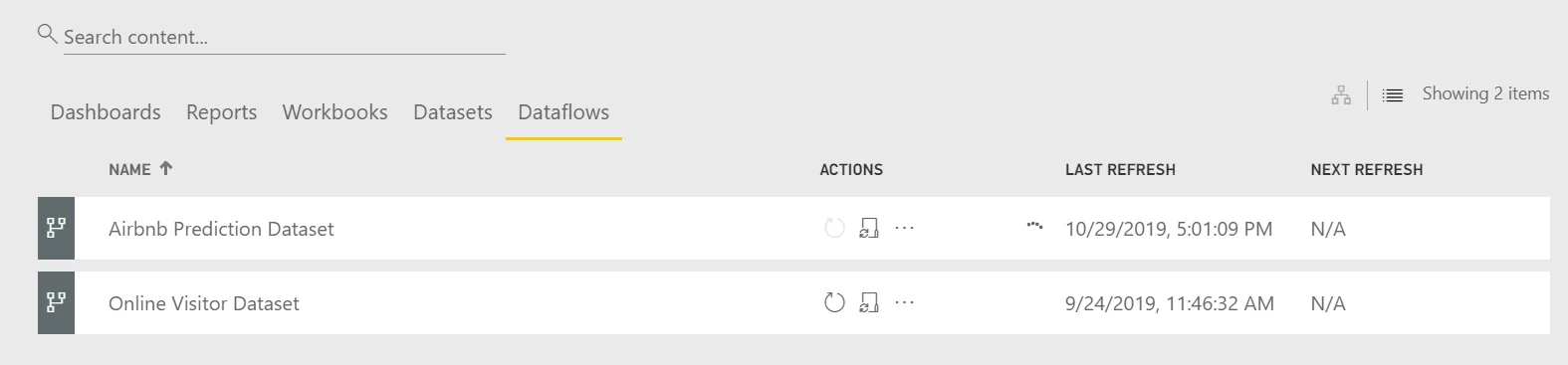
- After it has done training, select the dataflow. It will show the entity created by Auto ML.
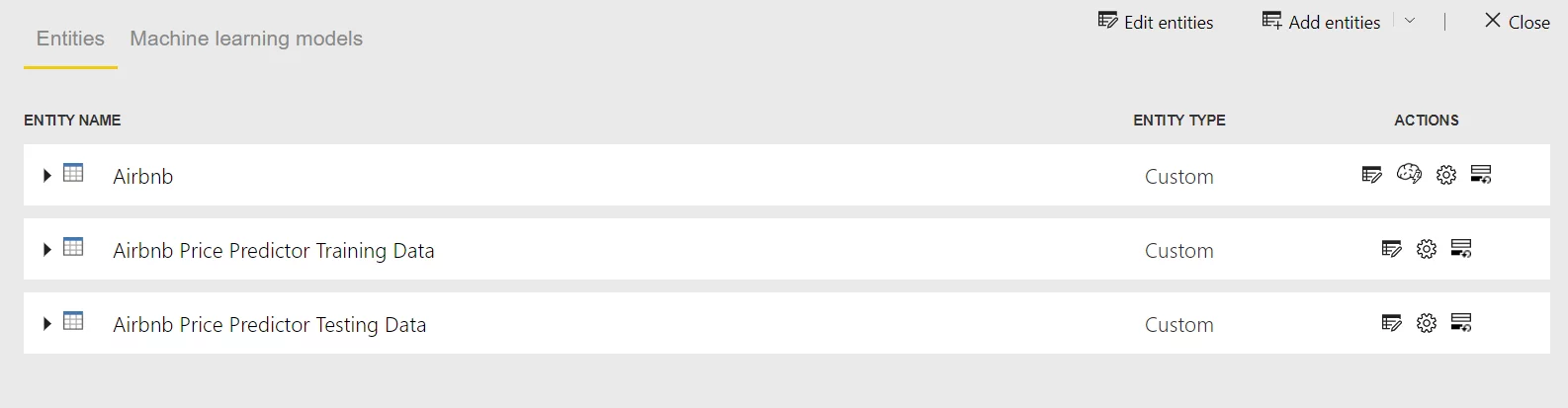
Airbnb is the entity we created at the start of the process.
Airbnb Price Predictor Training Data is the 80% split of the data on which training has been done.
Airbnb Price Predictor Testing Data is the 20% split of the data on which the model has performed validation to score how accurate it is.
The entities will display the steps Auto ML used for training and testing, making this an easy to follow and transparent process.
- Select Machine Learning Models tab, it will take you to the trained ML model.

The four highlighted options include:
Edit entity: Edit columns selected for model training and training time
Re-train model: Start training the model after performing changes in feature selection etc.
View Training Report: Directs you to the detailed report containing information about which algorithms the model ended up using for prediction, indicating key features/columns used for prediction, model accuracy details etc.
Apply ML Model: The trained ML model can be deployed on a dataset to gain results.
Remarks:
Now that the model has been trained, we can look at the model training report to see how well our model performs. After studying that, we can decide if it qualifies to be used in production. In Part 2 of this blog, we will explore the Model Training Report and unlock the details. We will also show you how to apply the trained model on a dataset.
If you have any questions about Automated Machine Learning using Power BI, feel free to leave a comment below!




