Processing 10 Million Records in Under 20 Minutes for a U.S.-Based Energy Drink Manufacturer
Processing 10M Records in Under 20 Minutes with Microsoft Fabric
Records/Day
Faster Processing
Data Variance
Delivery Time
Executive Summary
A global American energy drink manufacturer headquartered in Southern California’s Inland Empire, with one of the largest product footprints in U.S. convenience retail, needed a scalable data engineering solution to operationalize consumer behavior intelligence. As one of the top energy drink brands globally, with distribution across convenience, grocery, and on-premise retail channels, the organization had access to extensive market data from a leading B2B provider. However, it lacked the infrastructure required to ingest, validate, and transform approximately 10 million daily retail and consumer records into analytically ready insights.
AlphaBOLD designed and delivered a comprehensive ELT platform on Microsoft Fabric, enabling the executive team to access analytically ready data each day and convert raw transactional feeds into a reliable decision-making asset.
Before this implementation, leadership decisions were often delayed due to incomplete and unreliable data. Following deployment, executives now receive accurate consumer intelligence every morning, supporting faster market response, improved campaign planning, and greater confidence in data-driven decisions.
Business Environment
| Layer | Technology | Purpose |
|---|---|---|
|
Orchestration |
Data Factory |
Pipeline scheduling, parallelization |
|
Ingestion |
Copy Activity + REST API |
High-throughput data extraction |
|
Storage |
Lakehouse (Delta Lake) |
ACID transactions, time travel |
|
Transformation |
Spark Notebooks |
PySpark ETL, reconciliation |
|
Serving |
SQL Analytics Endpoint |
Semantic layer, ad-hoc queries |
|
Visualization |
Power BI |
Dashboards, operational metrics |
The Challenge
The client’s existing data architecture exhibited a common anti-pattern: data acquisition without corresponding data governance. Three critical deficiencies constrained operational effectiveness:
1. Ingestion Latency:
- Daily loads required 45+ minutes using sequential API calls with single-threaded processing. The existing Python scripts lacked connection pooling and retry logic, causing frequent timeouts during peak data volumes.
- This delay limited the organization’s ability to react to market trends and rendered same-day consumer insights unusable for decision-making.
2. Data Integrity Gaps:
- Source-to-destination variance measured 5–10% due to silent failures during API pagination, incomplete transaction handling, and the absence of checksum validation. No reconciliation mechanism existed to detect or correct discrepancies.
- As a result, executive dashboards could not be trusted, forcing teams to validate numbers manually before acting on insights.
3. Manual Remediation:
- When discrepancies surfaced through downstream reports, engineers manually queried source systems, identified gaps, and executed ad-hoc reload scripts; consuming 8-12 engineering hours weekly.
- This reactive effort diverted senior engineers from higher-value initiatives and introduced risk during critical reporting cycles.
Solution Architecture
Microsoft Fabric was selected to unify ingestion, engineering, analytics, and visualization within a governed platform, eliminating fragmented tooling and reducing operational overhead.
We designed a comprehensive ELT architecture leveraging Microsoft Fabric’s unified analytics platform, eliminating integration complexity while providing elastic scalability without infrastructure provisioning overhead.

Core Technical Components
Throughput at Scale:
Built on Data Factory pipelines with dynamic parallelism. The orchestration layer queries source metadata to determine daily record counts, then spawns proportional ForEach activities with configurable batch sizes (default: 50,000 records/batch).
This approach achieved linear throughput scaling; doubling the data volume doubles the copy activities without requiring manual intervention.
Data Trust & Accuracy:
Post-ingestion validation runs via Spark notebooks comparing source record counts against Lakehouse Delta tables. The system performs:
- Row-level checksums using MD5 hashing on composite keys
- Partition-level aggregation comparing SUM, COUNT, and MIN/MAX values
- Automated remediation triggering targeted partition reloads when variance exceeds 0.1%
Mean time to resolution (MTTR) dropped from hours to under 5 minutes.
Real-Time Observability Visibility:
A Power BI dashboard connected via DirectQuery surfaces pipeline telemetry including:
- Ingestion throughput (records/second) with 15-minute granularity
- Data accuracy percentages by source table and date partition
- Pipeline execution status with failure alerting via Microsoft Teams webhook
Semantic Transformation Layer:
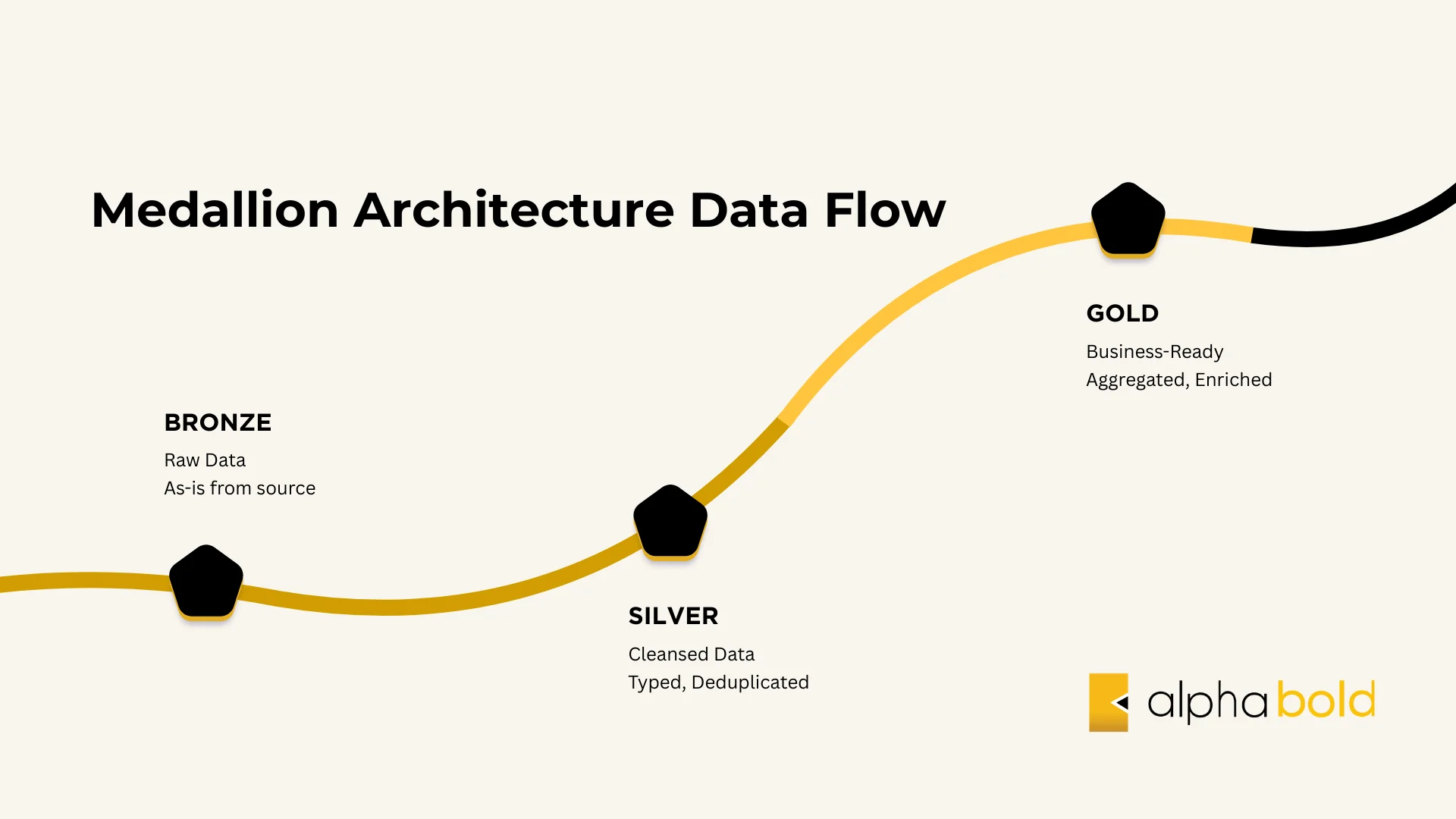
Raw data is stored in the Bronze layer (Lakehouse), then transformed through the Silver layer (cleansed and typed) to the Gold layer (business-ready) using the medallion architecture. Transformations include:
- Temporal alignment (UTC normalization, fiscal calendar mapping)
- Dimensional conformance (product hierarchy, geography standardization)
- Business rule application (promotional flags, customer segmentation)
Measurable Results
The platform went live in 8 weeks; half the originally estimated timeline. Performance exceeded internal benchmarks across every metric:
| Metric | Before | After |
|---|---|---|
|
Processing Time |
45+ minutes |
< 20 minutes |
|
End-to-End Cycle |
Variable |
< 30 minutes |
|
Data Variance |
5–10% |
0–2% |
|
MTTR |
8–12 hours |
< 5 minutes |
|
Project Timeline |
4 months (est.) |
8 weeks |
The architecture is designed to handle 10 times the current volume (100M records/day) without requiring structural modifications; this is achieved through Fabric’s auto-scaling compute and Delta Lake’s optimized storage layer.
Collectively, these improvements shifted data from a delayed reporting artifact into a reliable, near-real-time decision asset for leadership and analytics teams.
Modernize High-Volume Data Pipelines with Microsoft Fabric
Discover how Microsoft Fabric and expert data engineering can modernize your analytics infrastructure and deliver measurable business outcomes.
Request a Consultation





