Continuous Integration and Delivery for Machine Learning and AI using LLMs

Table of Contents
Introduction
Continuous Integration (CI) and Continuous Delivery (CD) are now central to modern software engineering, but applying them to Machine Learning (ML) creates a different level of operational complexity. ML and AI systems depend on changing datasets, retrained models, and outputs that are not always predictable. As organizations adopt Large Language Models (LLMs) and other advanced AI workloads, issues such as model drift, unstable performance, and reproducibility gaps become more visible and more costly.
Most existing DevOps pipelines cannot support these requirements. A standard CI workflow does not account for shifting data distributions. A simple deployment routine cannot track inference quality or trigger retraining. Without the right structure, even well-trained models begin to fail when exposed to real production behavior.
At AlphaBOLD, our experience with CI/CD for Machine Learning and AI shows that the teams who succeed are the ones who treat models, datasets, and pipeline logic as first-class software assets. This approach allows them to enforce version control, manage dependencies consistently across environments, and automate training, testing, and deployment in a controlled manner.
This guide outlines how to build reliable CI/CD for Machine Learning and AI using practices we apply in real client engagements. It covers versioning, containerization, automated evaluation, scalable deployment, and continuous monitoring. These components work together to deliver:
- Reproducible environments across development, testing, and production
- Automated pipelines that reduce manual intervention
- Stable, scalable, and cost-aware model deployments
- Early detection of performance issues and model drift
- A structured path for operationalizing AI at scale
A mature CI/CD foundation is the most effective way to maintain high-performing ML and AI systems as they evolve with new data, new requirements, and new business expectations.
How to Manage Machine Learning Models in Source Repositories
Effective version control is the foundation of any reliable AI development workflow. A Machine Learning model cannot be integrated, tested, or deployed consistently unless its code, data references, and configuration files are stored and tracked in a structured way. This is also the point where Continuous Integration for Machine Learning becomes possible, because every change is captured and evaluated through an automated process rather than manual coordination.
In enterprise environments, we recommend treating model assets the same way traditional software teams manage code. This includes training scripts, preprocessing logic, configuration files, dependency lists, and model artifacts. Placing them inside a centralized repository, such as GitHub or Azure Repos, ensures that engineering and data science teams work from synchronized versions instead of isolated local setups.
This approach provides three essential advantages:
- Traceability: Every change to the model, dataset pointer, or training logic is recorded.
- Reproducibility: Teams can recreate results by checking out specific versions of code and data definitions.
- Collaboration: Multiple contributors can experiment, review updates, and merge improvements without losing alignment.
In our project work, we have observed that this structure reduces environment-related failures and eliminates inconsistencies that often occur during AI deployment automation. Once models and dependencies are versioned correctly, organizations establish a stable foundation for automated training, evaluation, and deployment pipelines that support long-term AI operations.
How Containerized Architecture Improves ML and AI Deployments
The architecture behind a Machine Learning system has a direct impact on performance, stability, and operational cost. Traditional monolithic applications can run smaller workloads, but they become difficult to manage as organizations introduce more models, larger datasets, and higher inference demands. This is especially true for Large Language Models, where resource requirements shift based on user activity and model complexity.
A containerized approach resolves these limitations by separating application components into independent, lightweight units. Each unit contains only what it needs to run, including the specific version of a model, its dependencies, and the supporting runtime. This structure aligns well with Continuous Integration for Machine Learning because every container can be built, tested, and deployed automatically through a pipeline without affecting other services.
Key advantages include:
- Scalability: Containers can scale up or down based on traffic and inference load.
- Consistency: Environments remain identical across development, testing, and production.
- Cost efficiency: Compute resources are used only when needed, especially for GPU workloads.
- Simplified updates: Individual services can be upgraded or replaced without disrupting the full system.
- Higher reliability: Faults in one container do not spread across the entire application.
In our client implementations, containerization has reduced deployment time, improved model isolation, and allowed teams to experiment with new model versions without risking production stability. Combined with Kubernetes-based orchestration, it provides the control needed to support AI deployment automation at scale while keeping system behavior predictable and maintainable over time.
How to Implement CI/CD for Machine Learning and AI with LLMs
A reliable CI/CD workflow is essential for operationalizing Machine Learning models at scale. It ensures that each change, from data updates to model retraining, moves through a controlled sequence of validation steps before reaching production. This structure supports automation, reduces manual effort, and strengthens system reliability as models evolve. Continuous Integration for Machine Learning also creates a consistent path for promoting new versions across environments without introducing instability.
Continuous Integration (CI):
CI focuses on building repeatable environments for training and inference. By packaging models and dependencies into Docker images, organizations can eliminate discrepancies between local machines and production servers. These images are then versioned and stored in secure registries such as Azure Container Registry, ensuring that all environments reference the same build.
Storing and Versioning Docker Images:
Model images must be stored in a centralized, version-controlled location to maintain reproducibility and rollback capability. Using Azure Container Registry or Azure Blob Storage allows engineering and data science teams to track builds, compare versions, and ensure that testing, staging, and production environments run the correct image.
Build Reliability:
Cloud-managed build agents help standardize the CI process by removing variability from the underlying infrastructure. In our implementations, this setup limits failures to actual code issues rather than environment errors. It also creates a consistent path for building, scanning, and validating model images.
Environment Structure:
Maintaining separate development, testing, staging, and production environments prevents unvalidated code from reaching production. Staging environments should mirror production closely to verify performance, resource consumption, and behavior before release. This reduces deployment risk and supports compliance-driven workflows.
Deployment Strategy:
Deployment considerations depend on the type of model and the scale of inference. GPU-enabled virtual machines can support specialized workloads, while Azure Machine Learning offers managed orchestration for automated retraining pipelines. For real-time LLM applications, container orchestration with Kubernetes provides the flexibility needed to scale inference and manage parallel model versions.
In AlphaBOLD’s client work, this structured CI/CD for Machine Learning and AI approach has reduced deployment incidents, shortened release cycles, and provided a predictable path for pushing new model versions into production. The same pattern applies to LLMs, where dependency control and automated promotion become essential for stable, enterprise-grade performance.
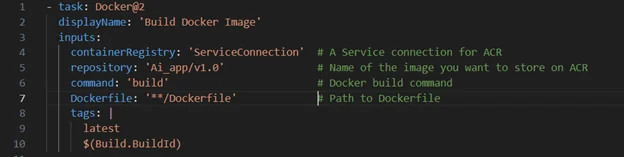
The following example shows a Docker task from an Azure DevOps pipeline that builds a container image for an AI model. This type of task helps standardize the CI process, ensures consistent image creation, and provides a reliable path for promoting versions across environments.
Strengthen Your AI Deployment Framework
A reliable CI/CD foundation ensures that Machine Learning and LLM workloads remain stable, reproducible, and ready for production. If you are planning to scale AI across your organization, our team can help you evaluate your current pipelines and identify practical steps to improve automation, testing, and monitoring.
Request a DemoYou may also like: Generative AI and ML for efficient support ticket prioritization
How Can LLMs Be Integrated and Applied in Enterprise Systems?
Large Language Models can operate as modular components within enterprise systems when supported by a structured deployment workflow. This allows them to handle tasks such as document processing, conversational interactions, and automated data transformation while remaining aligned with existing infrastructure and performance requirements.
Organizations often use customizable open-source models for greater control over data handling and internal configurations. Once deployed, LLMs support common use cases including chat-based interfaces, summarization, classification, multimodal processing, and automated workflow steps.
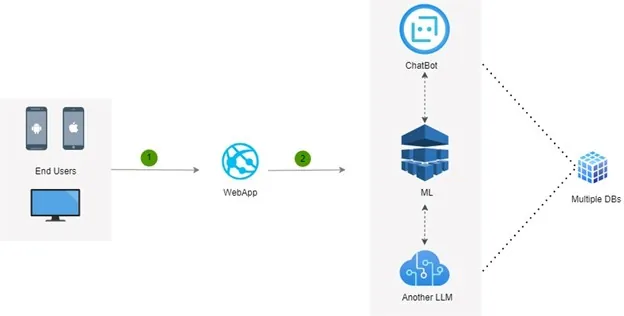
Integration Workflow:
Most enterprise LLM implementations follow a straightforward path:
- User interaction: A frontend application collects inputs such as text, images, or files.
- Model processing: The LLM handles inference and generates the required output.
- Data storage: Results are stored in SQL or NoSQL systems based on their structure.
- Model improvement: New data and feedback are used to retrain models and maintain accuracy.
You may also like: Energy Drink Makers Use ML for Clean, Actionable Data
What are the Key Challenges in ML and AI Projects?
Building and maintaining Machine Learning systems in production introduces challenges that traditional software pipelines do not encounter. Models depend on evolving data, shifting usage patterns, and complex dependencies. Without a structured process for versioning, testing, and monitoring, performance begins to degrade quickly. These challenges also highlight why CI/CD for Machine Learning and AI is necessary to maintain reliability at scale.
1. Versioning Data and Model Updates:
Models change as new data becomes available, which makes controlled versioning essential. Teams must track dataset revisions, training configurations, and model artifacts to ensure reproducibility and prevent conflicts across environments.
2. Automated Testing for Code and Models:
AI pipelines require automated tests that evaluate both code quality and model behavior. Functional tests, performance checks, and security scans help confirm that each model version meets accuracy, latency, and reliability requirements before deployment.
3. Monitoring for Drift and Anomalies:
Once deployed, models must be monitored for accuracy changes, shifts in input data, and performance issues. Early drift detection prevents model degradation and provides signals for retraining or rollback.
4. Managing Dependencies and Compute Resources:
ML and LLM workloads involve libraries, GPU requirements, and framework updates that can break pipelines if unmanaged. Consistent environments and validated dependencies reduce deployment failures and integration issues.
In our client projects, these challenges appear early when organizations scale beyond initial prototypes. Addressing them with clear versioning practices, automated testing, and robust monitoring leads to more stable deployments and shorter iteration cycles. It also ensures that production systems continue to operate as expected as data, demand, and business requirements evolve.
Testing and Monitoring in CI/CD for Machine Learning and AI
Reliable Machine Learning systems require automated checks that validate every model version before release and continuous monitoring once the model is running in production. These steps ensure stability, accuracy, and predictable behavior across environments, especially as data and usage patterns change.
Automated tests confirm that model code, configurations, and dependencies are functioning correctly. Performance tests evaluate latency, throughput, and resource usage to verify that services meet real-time requirements. Security scans help identify vulnerable dependencies and misconfigurations early in the pipeline.
After deployment, models must be monitored for accuracy shifts, data quality issues, and unexpected changes in behavior. Drift indicators, inference latency, and error rates provide signals for retraining or rollback. This approach helps maintain consistent model performance over time and supports the continuous improvement of AI systems.
Prepare Your Organization for Scalable AI Operations
Consistent pipelines reduce deployment risk and help teams move AI initiatives from experimentation to reliable production use. Connect with our experts to understand the steps needed to create a long-term, maintainable deployment structure.
Request a DemoGuidelines for Reliable CI/CD in Machine Learning and AI Systems
Operationalizing Machine Learning models requires processes that support reproducibility, stability, and controlled iteration. The following principles form the foundation of effective CI/CD pipelines for AI systems:
- Treat models, data references, and code as unified versioned assets to maintain consistency across environments.
- Use automated pipelines to handle training, validation, packaging, release, and promotion of models.
- Monitor deployed models continuously to identify accuracy changes, performance degradation, or resource spikes.
- Define clear retraining triggers to address drift and maintain model reliability as new data becomes available.
- Use containerization and orchestration to ensure predictable deployments and efficient scaling.
- Enforce controlled environment promotion to ensure that only validated model versions reach production.
These practices help organizations maintain long-term reliability while supporting faster iteration and more stable deployment cycles.
Before setting up your CI/CD workflows, review our Checklist: Preparing Your Business for AI Implementation to ensure you’re ready for scalable AI adoption.
Invest in Your AI Deployment Speed with AlphaBOLD
Ensure that every AI model you deploy is thoroughly tested, versioned, and continuously monitored through automated CI/CD pipelines.
Request a DemoConclusion
A structured CI/CD framework brings consistency, reproducibility, and control to Machine Learning and LLM deployments. By standardizing how models are versioned, tested, packaged, released, and monitored, teams can operate AI systems with greater confidence and efficiency. This approach also reduces operational risk as models evolve with new data and changing business needs.
For organizations planning to expand their use of AI, strengthening CI/CD for Machine Learning and AI foundational practices is a critical step toward sustainable, production-grade deployment.
FAQs
It standardizes how model code, configurations, and dependencies are packaged and validated, ensuring consistent behavior across environments.
They allow teams to test and validate model changes without affecting live systems, reducing the risk of unexpected issues in production.
Use version control for data references and model artifacts to ensure reproducibility and controlled promotion across environments.
ML systems benefit from functional tests, performance tests, and security scans that confirm accuracy, stability, and safe operation.
Monitoring detects drift, latency fluctuations, and anomalies, providing signals for retraining or rollback to maintain reliability.
Explore Recent Blog Posts





