
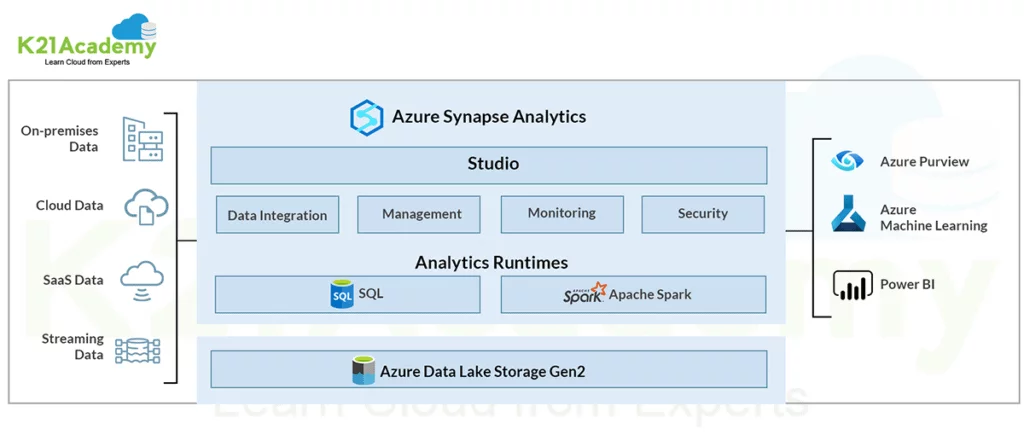
Azure Synapse is a scalable and cloud-based data warehousing solution provided by Microsoft. It is a business intelligence solution that combines data integration, data warehousing, and big data analytics capabilities. Azure Synapse gives you a unified experience of ingesting, exploring, transforming, and managing data for Machine Learning and Business Intelligence needs. It provides you with the option of querying data using either serverless or dedicated resources.
Learn more about our DevOps Services
Serverless Computing
Serverless Computing is a method of providing backend services, eliminating the need to manage infrastructure. It enables developers to write and deploy code without worrying about the underlying infrastructure, which allows them to focus more on the business logic and deliver massive value to their businesses. Physical servers are still used in serverless computing but are invisible to the developers. This helps increase productivity, allows optimizing resources, and provides them with a cost-effective solution.
It automatically scales and manages the resources required to run the code. In Serverless Computing, users are charged based on the computations they make. They do not have to reserve the resources and pay a fixed amount for them. It is an auto-scaling service, and you only pay for what you use.
Benefits of Serverless Computing
Here are some of the benefits of serverless computing:
- No Infrastructure management
- Cost-efficient (As developers are only charged for what they use)
- Inherently scalable
- Quick deployments
- Lower latency
- Efficient use of resources
Serverless SQL Pool in Synapse
Serverless SQL Pool is an auto-scale SQL query service that comes built-in within Synapse Analytics. It provides users with TSQL capabilities to run SQL queries on files placed in Azure Storage. This is done without the need for provisioning underlying hardware or software resources. It requires no maintenance of clusters or setting up infrastructure. It can read files directly from the data lakes and does not store data. It uses pooled resources internally; thus, it is named Serverless SQL pool. Serverless Computing uses a pay-per-use model and helps customers with ad-hoc querying. You will only be charged for a query if you run it to process data. . There are no charges for managing the infrastructure or for reserving the resources. This helps control the bill in a better way, enabling the users to approach the budget and forecast.
Architecture
Like Dedicated SQL Pool, Serverless SQL pool also distributes processing across multiple nodes using a scale-out architecture. Also, computer and storage are separate from one another in serverless SQL Pool, just like dedicated SQL pool. This allows compute to scale independently of your data.
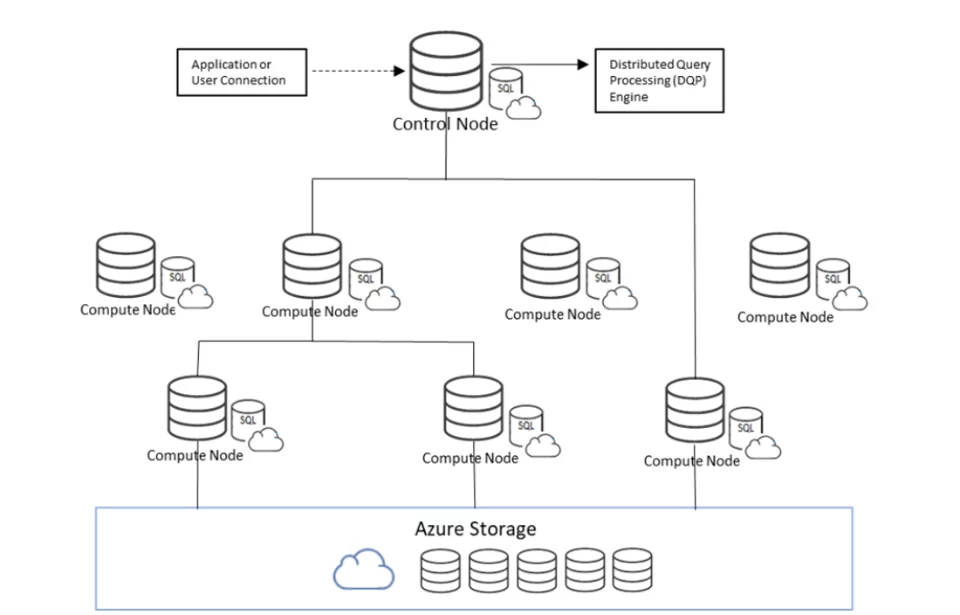
One of the key architectural differences between both dedicated and serverless SQL pool is that dedicated SQL pools use Massively Parallel Processing Engine to distribute queries in parallel across compute nodes. Also, dedicated SQL Pools use the provisioned unit of scale, i.e., Data Warehouse Unit (DWU), to determine the computer power.
On the other hand, a serverless SQL pool uses a Distributed Querying Processing (DQP) engine. This assigns tasks to compute nodes to complete a query. In the following diagram, you can see a query is passed to the central Control Node that uses the DQP engine. DQP engine determines the number of tasks that need to be done to complete the query and then assigns them to four computer nodes. The number of nodes is also decided by DQP based on the number of tasks. In this way, serverless SQL pool can scale automatically to accommodate any querying requirement.
Benefits of Serverless SQL
- Allows you to use SQL to work with files on Azure storage.
- Query data in Azure storage directly using T-SQL.
- Creates a Logical Data Warehouse on top of Azure Storage.
- Easier Data transformation of Azure storage files.
- Supports all the tools or libraries that use T-SQL for querying data.
- Automatically synchronizes tables from Spark pool.
- No infrastructure management
- No upfront cost and resource reservation
- Autoscaling
- Automatic schema inference
- You only have to Pay for query execution (per data processed)
Explore Azure Synapse Solutions
Use Cases
Serverless SQL Pool requires no infrastructure to set up or cluster to maintain, because of being serverless. It auto-scales according to your query needs and allows you to start querying data stored in Azure Storage as soon as you have established a Synapse workspace.
A serverless SQL Pool has several use cases, some of which are mentioned below:
- By using Serverless SQL Pool, you can explore and discover data in Azure Storage quickly and on-demand just like you would do with a table in SQL Server.
- Create a logical data warehouse by creating transformation views and external tables that provide you with SQL metadata layer over the data in the lake, directly querying from your raw ADLS Gen2 (Data Lake) storage layer. The clients don’t know that the data is in the data lake so serverless SQL Pool acts as a lightweight layer between data and clients.
- Simple transformation of data in Azure Storage for use in other BI systems.
- Build data visualization layers in Power BI, directly querying against Spark Tables.
- Data Spelunking: Investigatory work on data in data lake.
- Reviewing data processed in Spark Pool
The final decision of Whether to employ the serverless SQL pool or not ultimately depends on the individual use cases and cost-benefit analysis. You can decide, keeping in mind your requirements and workloads, whether optimal option serverless SQL pool or a dedicated resource like dedicated SQL pools is a better choice.
Cost
A pay-per-use pricing model is used for the serverless SQL pool. The cost is determined per TB of data processed by the queries you perform. Dedicated SQL pools, on the other hand, require you to pay for a reserved resource on a pre-determined scale. The current estimated cost of a serverless SQL pool is $5 per TB of data processed, therefore prices can quickly rise if queries are run on exceptionally large multi-TB datasets.
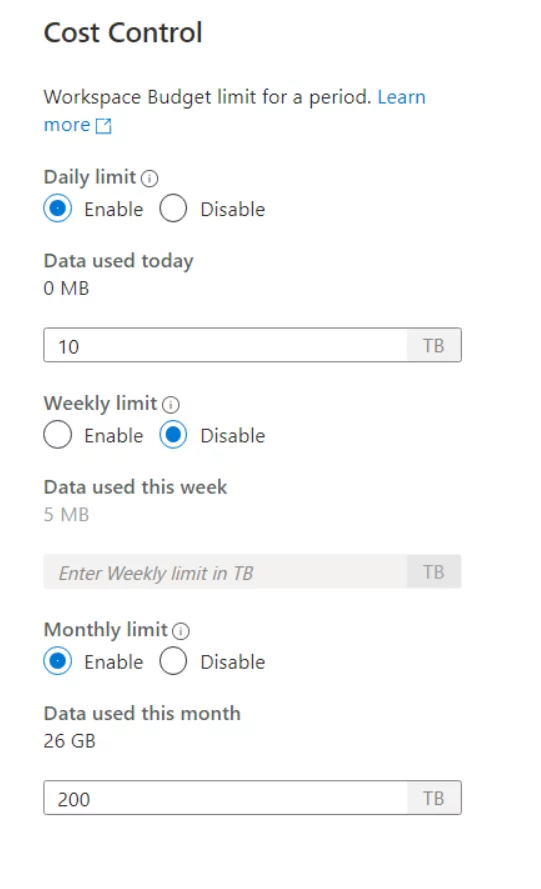
You can also set your budget in serverless SQL Pool which helps you in controlling your cost. For this, you can use synapse studio or T-SQL. This enables you to limit your budget to the amount of data processed for a specific period (day, week, or month).
Conclusion
In this blog, we have discussed serverless computing and how Azure Synapse implements it. Azure Synapse Serverless SQL Pool makes it easier for data scientists and analysts to engage with the data lake and gives faster insights. Serverless SQL Pool employs distributed processing, in which a control node optimizes the query and executes it in parallel by distributing it to the compute nodes. T-SQL is a programming language that is used to read, manipulate, and export data. It is a pay-per-query model in which you only pay for the data that your query processes, making your solution more cost-effective