Introduction
This is the fourth blog in the series of blogs regarding time series forecasting in the Azure Machine Learning Service (AutoML). In the first blog, we learned about time series forecasting and Azure Machine Learning Studio. In the second blog, we used an open-source orange juice dataset to train a machine learning model. At the end of that blog, Azure Machine Learning Service provided us with a Voting Ensemble model as the best model for our data. In the third blog, we looked at the top 10 skills to take a time series forecasting model to the next level. In this blog, we will look at the two modes of inferencing in Azure Machine Learning i.e., real-time and batch inferencing. Finally, we will create a batch inference pipeline and will publish it in our Machine Learning workspace to take our time series forecasting model to production. All the Python code provided below is available at the following repo:
Modes of Machine Learning Model Deployment
Once we have a machine learning model, the next step is to take it to production. Azure Machine Learning Service provides two main ways of deployment of machine learning models:
- Real-time inferencing solution
- Batch inferencing solution
Real-time Inference Solution using Azure Machine Learning Service
A real-time inference solution is the one in which predictions are generated in real-time or as soon as a new data point is created. This requires a Kubernetes cluster for deployment. This follows a dedicated resource pricing model; therefore, it can be costly. However, the forecasts are generated in real-time. The most common use cases for real-time inference are fraudulent transaction detection, recommender engine, etc. In case of fraudulent transaction detection, we need the machine learning model to quickly identify fraudulent transactions so that appropriate actions can be taken. Therefore, this use case will require a real-time inference solution.
Batch Inference Solution using Azure Machine Learning Service
In batch inferencing solution, the inference on new datapoints is done in batches that may contain one row to thousands of rows. Batch inferencing pipelines are usually scheduled to run on a daily, weekly, or monthly schedule depending on the use case. They can also be triggered based on certain events such as new data points written on blob storage. All new data points are collected until the scheduled time, or till the trigger event happens. The compute resources required for batch inference are used in the pay-as-you-go model. When a batch inference pipeline is triggered, compute resources are acquired, and the machine learning model makes predictions against the batch of new data points. The most common use case of batch scoring inference is sales or demand forecasting. In our case of orange juice sales forecasting, we need to implement a batch scoring solution so that we can get predictions on a weekly or monthly basis depending on the business requirements.
Explore AI Solutions
Taking Time Series Forecasting Machine Learning Model to Production
Now that we know the two deployment modes available in Azure Machine Learning Service, it is time to take our orange juice forecasting model, that we created in the second blog, to production. As discussed above, we need a batch inference pipeline so that we can generate predictions and plan business processes based on those predictions.
For this, first, navigate to the Machine Learning service that we have already created. We need to start the compute instance that we previously created and open a new notebook. If unsure about any of these steps, refer to the first and second blog of this series.
Step 1: Importing Machine Learning Libraries required for Batch Inference Pipeline
First, we import all the libraries that we need for the proceeding code.


Step 2: Create Batch of New Data Points to Generate Forecasts
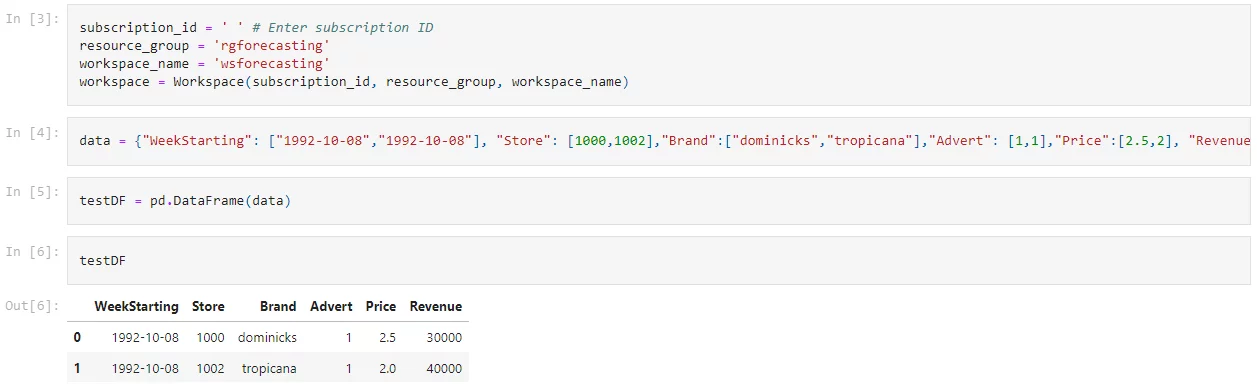
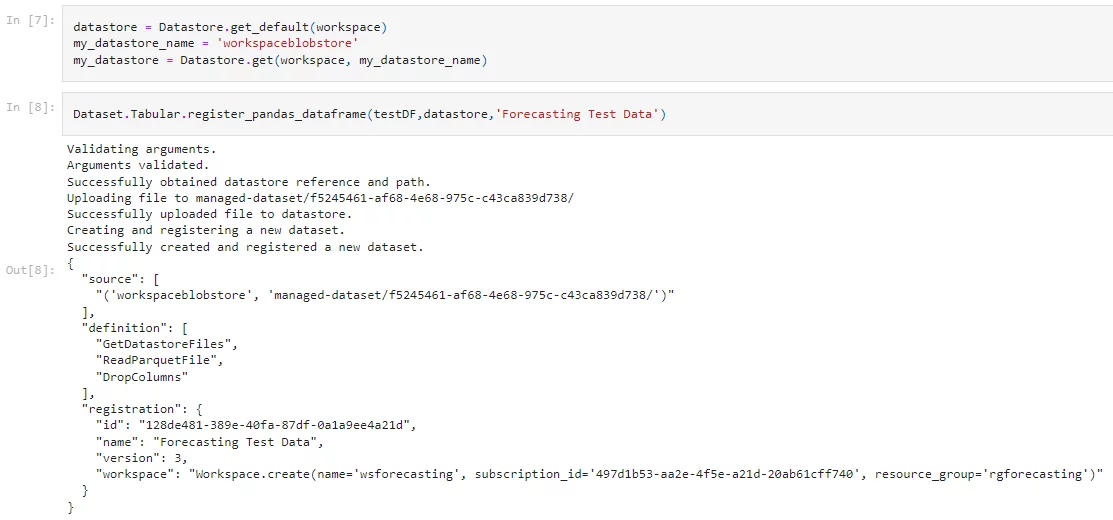
Once we have all the required libraries, the next step is to create a batch of new data points against which we will generate forecasts using our previously created machine learning model. In the example below, we create a small sample dataset for points in the future (i.e., dates that were not present in the training dataset). We need to register this dataset in our workspace. Make sure to replace the subscription id, resource group, workspace name according to your resources.
Step 3: Writing a Python Script to load the Machine Learning model and Generating Forecasts against New Data Points
Once we have a batch of new data points that we can input into the machine learning model then we need to write a Python script in ‘.py’ format that we can encapsulate in a ‘step.’

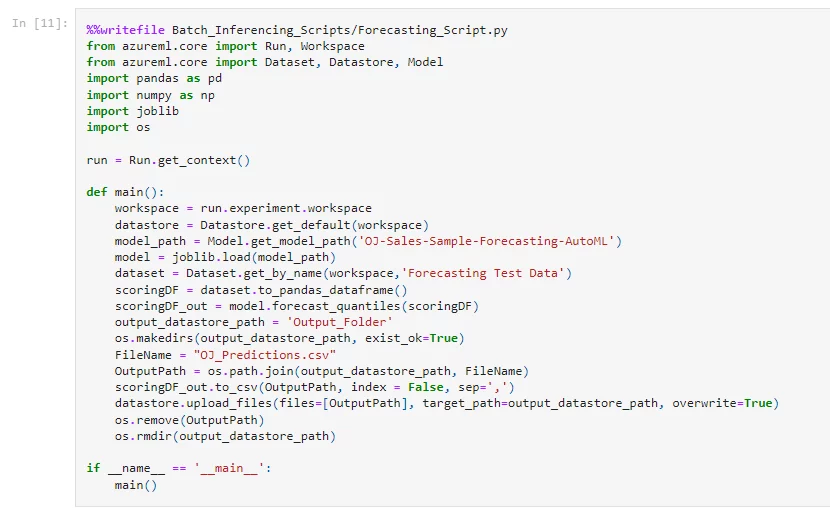
The above script loads the machine learning model and the batch test data from the workspace and generates forecasts against it. The forecasts are stored as an “OJ_Predictions.csv” file in our blob storage inside a folder called “Outpt_Folder”
Step 4: Curating a Custom Machine Learning Environment for Inference Script
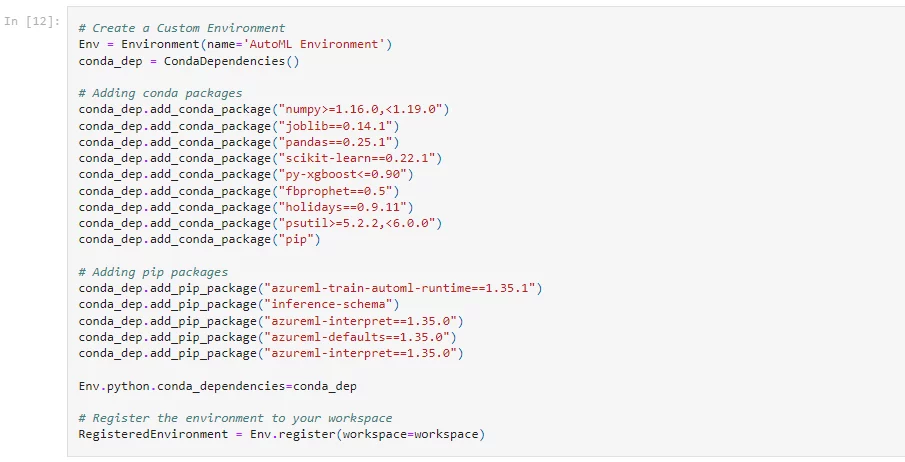
Once we have the Python script that we will use to load the machine learning model, we need to provide the script with an environment that will contain all the dependencies required to run that script. We can also register this custom script within our Machine Learning workspace for future use.

Step 5: Configuring a Step containing Python Script and encapsulating it within a Pipeline
So far, we have created a test dataset and registered it within our workspace. We have also created a Python script that can load a machine learning model registered within our workspace. We have also created an environment that contains all the dependencies required for the Python script to work. The next step is to encapsulate that script within a ‘step’ and that ‘step’ itself is encapsulated within a ‘pipeline.’ A machine learning pipeline can contain one or more steps that can run in sequence or parallel and can even accept parameters or pass on data between each other.

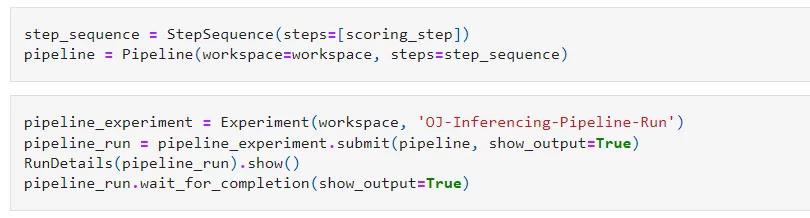
Once we have executed the last cell, it will run the inference pipeline on our compute cluster. We can view its progress in our Notebook or from Azure Machine Learning studio:
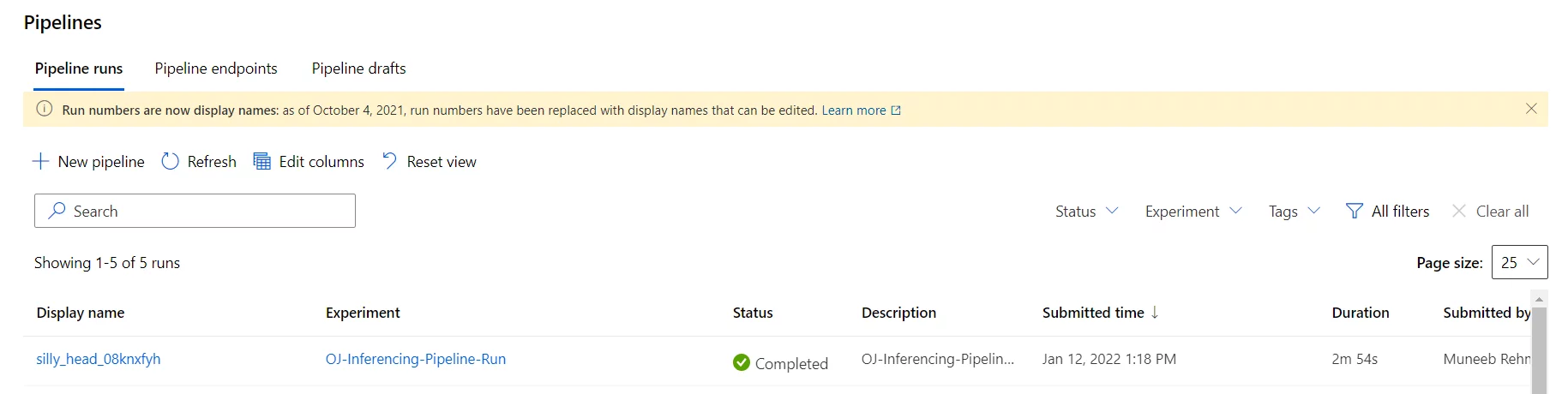
Step 6: Publishing the Batch Inference pipeline as a REST endpoint
Once we have successfully executed the batch inference pipeline, the next step is to publish it in our workspace as a REST endpoint. Once published, the pipeline can be scheduled or can be requested to run inference on new data points. All we will need to do is to replace the test dataset with the new data points on which we need to generate forecasts.

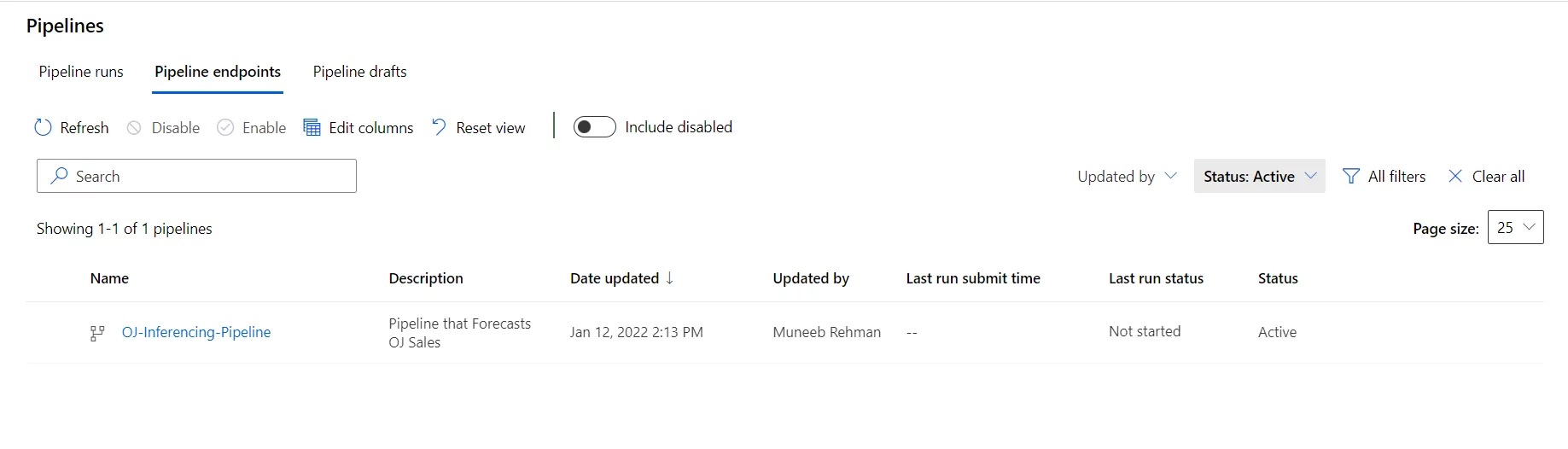
We can also view the published batch inference pipeline in Machine Leaning studio as below:
Step 7: Consuming the Results of the Batch Inference Pipeline
Previously, we created a folder with the name “Ouput_Folder” in our Python script and we saved the results of forecasts inside that folder as OJ_Predictions.csv file. So, navigate to the blob storage for the output file:
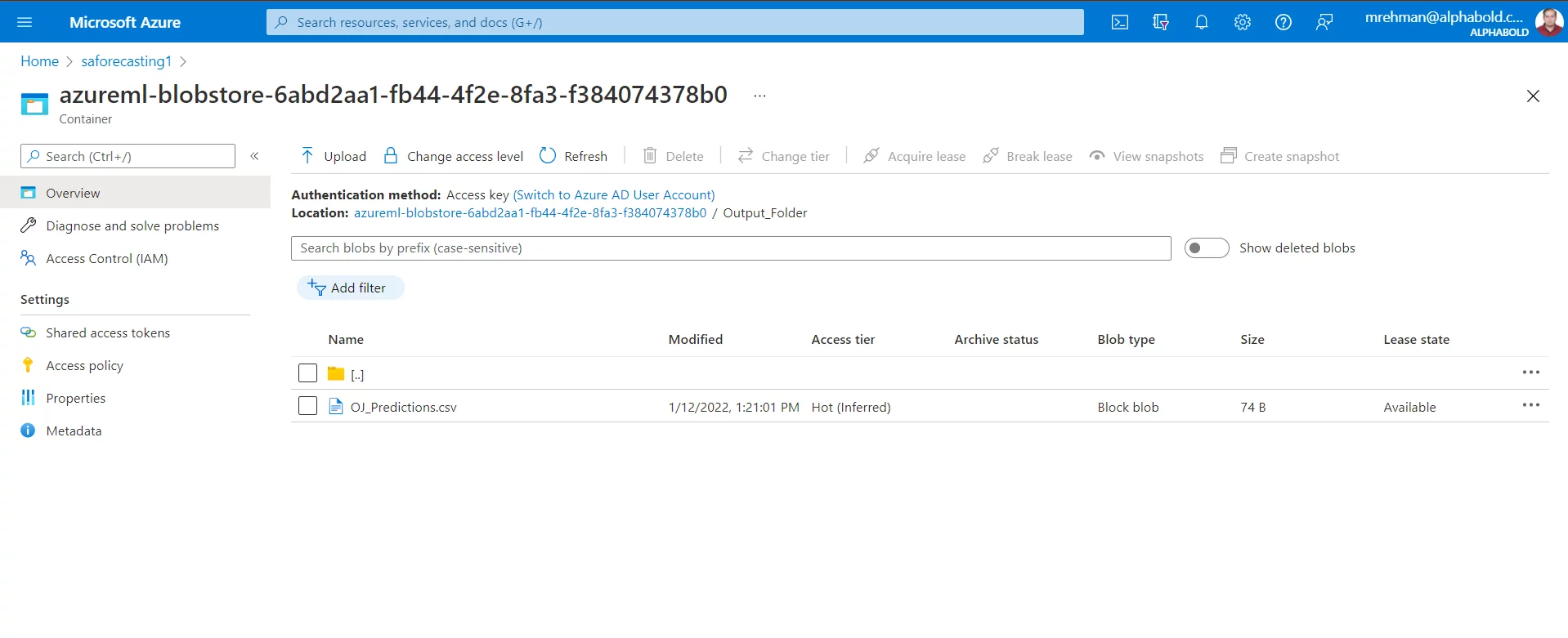
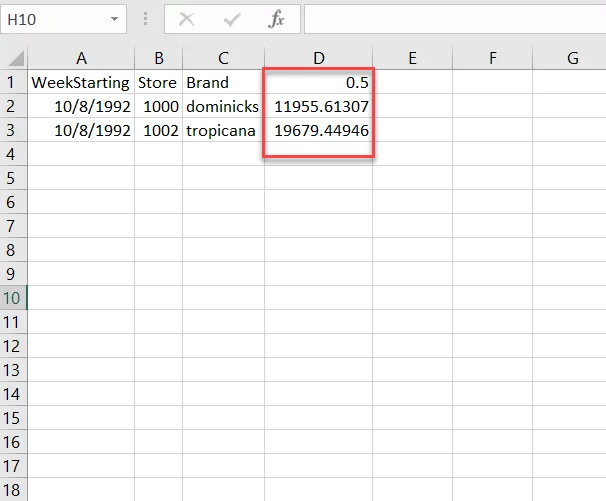
If you download the file and open it in excel, you will see that the file contains an additional column with the prediction sales as below. Recall that in our previous blog, we designed the machine learning model to use only the ‘Store’ and ‘Brand’ columns other than the ‘WeekStarting’ column. Therefore, the predictions file does not contain these two columns.
Conclusion
Finally, we now have a time series forecasting model deployed as a batch inference REST endpoint. Once we have this endpoint, we can run it on schedule or based on events to generate forecasts against new data points. Along the way, we also learned how to curate environments and design steps and pipelines in Azure Machine Learning Service. As can be seen, along with simplifying the model generation and selection, Azure Machine Learning Service has also simplified operationalizing the machine learning models.
In case you missed previous blogs of this series. You can read them through the links below:




