Time Series Forecasting using Azure Machine Learning: Top 10 Tips to take your Time Series Forecasting Model to the Next Level

Introduction
This blog is the third in our series on time series forecasting using Azure Machine Learning Service. In the second blog, we trained a time series forecasting model using Azure Machine Learning Service (AutoML). Time series forecasting is not just a skill; it is an art; in this blog, we will learn the top 10 tips to make our forecasting model perform reliably per business needs.
1. Frequent Errors in Azure Machine Learning Service during Time Series Forecasting Experimentations
You will frequently encounter specific errors if you are not careful in data cleaning or are still learning the art of time series forecasting on Azure Machine Learning Service (AutoML). Make a note of these errors because you will most likely encounter these cases in your data preparation and transformation pipeline:
Learn more about Business Intelligence!
Duplicate Rows:
Error: “Found duplicated rows for [Invoice_date] and [‘grain’] combinations. Please make sure the time series identifier setting is correct so that each series represents one-time series or cleans the data to make sure there are no duplicates before passing to AutoML. If the dataset needs to be aggregated, please provide freq and target_aggregation_function parameters and run AutoML again.”
You get this error when you do not prepare the data to conform to a consistent series. For example, your time series identifier columns are ‘store’ and ‘product,’ and you use daily sales data for training. Then, you must have one row per combination of store and product per day. If you have more than one, then you need to aggregate.
Inconsistent Frequency:
Error: “The frequency for the following time series identifier is inconsistent. The expected frequency is a data point every ‘<week: weekday=6’. Review the time series data to ensure consistent frequency alignment and specify the frequency parameter.”
This error is like the first error. For this, you must ensure that the time series frequency is consistent, i.e., you do not have any missing rows. For example, if you have weekly data, ensure one row every week for every time series. If you do not, then you need to impute the missing values.
Target Value:
Error: ‘At least two distinct values for the target column are required for the forecasting task. Please check the values in the target column.’
You will get this error if you only have one unique value per time series in your training dataset (excluding the validation dataset that Azure AutoML splits behind the scenes). In this case, it is not a machine learning problem. Consider excluding such time series from the input dataset or increasing the input data frequency (e.g., convert weekly data to daily data) to decrease the likelihood of such cases.
Varying Frequencies:
Error: ‘More than one series in the input data, and their frequencies differ. Please separate series by frequency and build separate models. If frequencies were incorrectly inferred, please fill in gaps in the series. If the dataset needs to be aggregated, please provide freq and target_aggregation_function parameters and run AutoML again.’
You cannot run a single experiment for varying frequencies. For example, if you have two different time series, one with daily data and the other with weekly data, consider converting them to weekly data or train separate models for them.
Training Time:
Error: ‘Run timed out. No model completed training in the specified time. Possible Solutions:
- Please check if there are enough computing resources to run the experiment
- Increase experiment timeout when creating a run
- Subsample your dataset to decrease featurization/training time’
For this error, the solutions are given within the error message.
Early Stopping:
Error: ‘No scores improved over the last 20 iterations, so the experiment stopped early. This early stopping behavior can be disabled by setting enable_early_stopping = False in AutoMLConfig for notebook/python SDK runs.’
In some cases, as Azure AutoML will run experiments trying various algorithms and hyperparameters, the model’s performance will stop improving after some runs. In that case, Azure AutoML will terminate the experiment by default. You can override this behavior if required.
Scoring:
Error: ‘Scoring data frequency is not consistent with training data frequency or has different phase’
Scoring means getting predictions from your trained model. Here, you need to be careful that if you have a model trained on weekly data (every Monday), you can only get predictions per week (Monday) for the number of weeks specified by the forecast horizon.
Start your Azure-Powered Analytics Journey!
Explore Azure's capabilities to empower your data with smarter solutions and strategic insights. Together, let's harness the full potential of Azure Machine Learning.
Request a Consultation2. Do not drop a Business Column when doing Feature Engineering
The first and foremost rule of designing a dependable machine-learning-based Artificial Intelligence (AI) solution is to ensure that the modeling exercise meets the business needs. This is true for all machine learning models. Still, it is more important for time series forecasting models because higher data quality requirements mean you may have to drop a particular feature because of questionable quality. However, if the business requirements include that feature, it is not a feature-selection problem but rather a data-cleaning problem.
Explore AI Solutions for Your Business
3. Use ARIMA (Auto-Regressive Integrated Moving Average) and Prophet Machine Learning models as a baseline
ARIMA and Prophet models are your baseline models for time series forecasting and provide you with a good baseline performance only against the time column, time series identifier, and target variable. Azure Machine Learning service provides both these models in AutoML experiments. Therefore, it is recommended to first experiment with ARIMA and Prophet as the only allowed models. Only after this should you increase features and try other models to see if they perform better than these models.
4. Do not use Regression models for Time Series forecasting problems
Though both regression and time series forecasting models predict a continuous number, they differ. We only make predictions in the future in time series forecasting, so time is the critical dimension here. This also results in additional requirements and limitations for time series modeling problems. For example, random data splitting in testing, training, and validation sets will not work here. Similarly, standard cross-validation will also not work. Azure AutoML uses Rolling Origin Cross-Validation (ROCV) for time series forecasting problems. ROCV slides the origin in time to generate cross-validation sets as shown below:
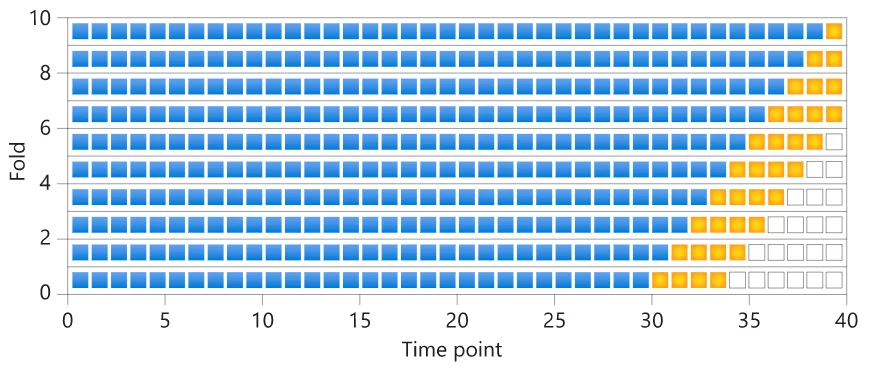
5. Use retraining Pipelines
As discussed earlier, what differentiates time series forecasting from regression and classification problems is that time is the critical feature in the former. A time series model must be retrained to learn from new data. Therefore, it is imperative to design retraining pipelines. A good time series forecasting model should give more weightage to recent data than to old data.
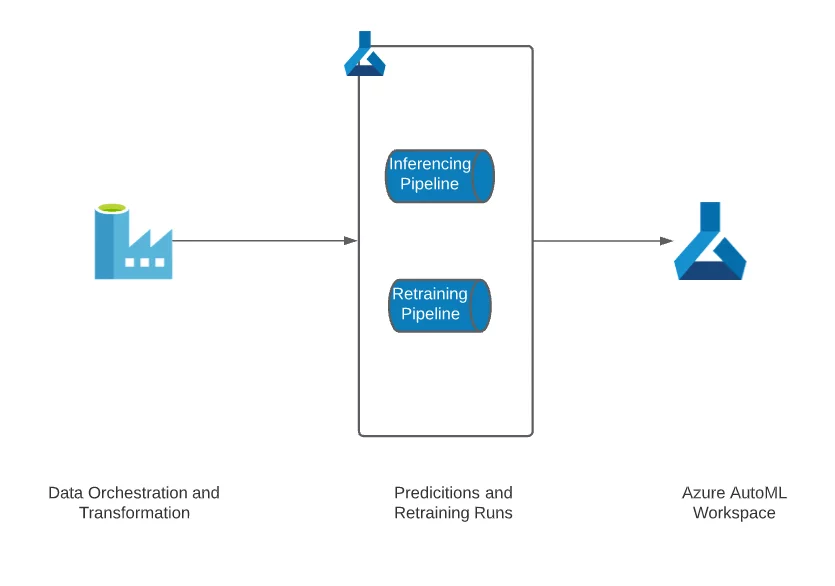
6. Start with core features
It is highly advisable to only start from core features such as time series identifier (also called grain columns), time column, and the target column. Once you have a baseline model on the core features, then you can add additional features such as:
- Datetime features (day of the week, the season of the year, etc.)
- Lag features (sales same-day-last-year, sales same-day-last-month, etc.)
- Window features (average sales for the last three months, etc.)
Azure AutoML adds these features to your dataset if you enable them in your forecasting parameters (as seen in the last blog).
7. Start with a subset of data
Apart from complexity, training machine-learning models on the cloud incurs costs. Therefore, selecting a subset of data and starting using it to train machine learning models is better. Once you understand the data, the Azure Machine Learning service, and a baseline performance threshold, you can scale to complete data and see how the new model performs. For example, if you have three years of data, it is better to start with the most recent year of data and train models using that data. Once you understand the needs of the business, data, and Azure AutoML, you can scale out and run experiments on complete data.
Read more: Time Series Forecasting using Azure Machine Learning Service
8. Choose the frequency of data and Forecast Horizon carefully
It is imperative to select the frequency of the data carefully. This will depend on several factors, including business needs, data availability, and data quality. Whatever your frequency of time series data, you will be able to forecast values in the future as a factor of the time series frequency. This is called Forecast Horizon. For example, if you have weekly data, i.e., one row per time series per week, a forecast horizon of 3 means you can forecast three weeks into the future.
Optimize Forecasts with Azure's AI Insights!
AlphaBOLD is your partner in integrating Azure's AI insights into your Power BI projects for sharper, more accurate forecasts. Take the first step towards optimized predictive analytics with us.
Request a Consultation9. Resampling the input data vs Aggregating the Predictions
Resampling the input data means changing the frequency of the input data before it is used to train a machine learning model. For example, if you have daily sales data, you can aggregate it to get weekly sales data and then train a machine learning model to make predictions on a weekly level. In this case, however, you will not be able to get forecasts on a daily level.
On the other hand, you can train a model on daily sales data, get predictions on daily frequency, and then aggregate the daily level predictions to get weekly sales predictions.
Here, it might sound like training on a daily level is a better idea. However, in practice, you must consider many factors when deciding on the input data sample, e.g., training time, data availability, computational limitations, business use case, etc. Consider the following comparison for the above-stated example where you down-sample the input data (daily to weekly sales) before training vs. predicting on a daily level and then aggregating the predictions to get weekly forecasts:
| Downsampling the data before training | Aggregating the predications |
|---|---|
|
Less computing for training runs |
More computing for training runs |
|
Less training time |
More training time |
|
Cannot get predictions on a finer level |
Can aggregate the predictions |
|
Risk losing the variations and patterns on a finer level |
Do not lose variations and patterns on the daily level |
|
A smoother curve for output variable as you downsample on weekly level |
More susceptible to noise |
Recall: Time series data points are made of four essential elements:
- level (average value)
- trend (increasing/decreasing)
- seasonality (repeating short term cycles)
- noise (random variations in the series)
10. Spend time on Data Preparation
Finally, spend time on data cleaning and preparation. Most of the time is spent cleaning and analyzing the data in any data science project. However, it is more important in time series forecasting because of stricter data quality requirements. Azure AutoML also has some data quality requirements as it runs some data guardrail checks.
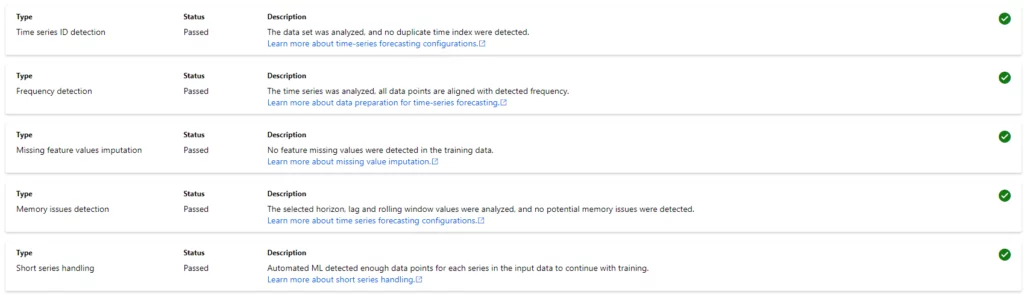
Conclusion
In this blog, we have looked at numerous ways to ensure that we train dependable and high performing time series models. In the next blog, we will deploy our trained and registered model from the second part of our series in an automated batch scoring pipeline to get an end-to-end machine learning solution.






