In today’s rapidly evolving digital landscape, aligning business strategy with technical agility is paramount. Enter DataDevOps – a collaborative methodology that bridges the gap between data-driven business goals and agile data solutions. DataDevOps, sometimes termed as “Data Operations for modern enterprises,” streamlines data workflows and offers transformative business benefits when combined with Azure’s robust cloud platform. By leveraging the power of DataDevOps on Azure, organizations can drive improved decision-making, foster quicker time-to-market, and ensure a competitive edge in the age of big data and analytics. This article provides a strategic overview of the compelling advantages of DataDevOps for business leaders while also delving into actionable insights for those tasked with its implementation.
Data Factory
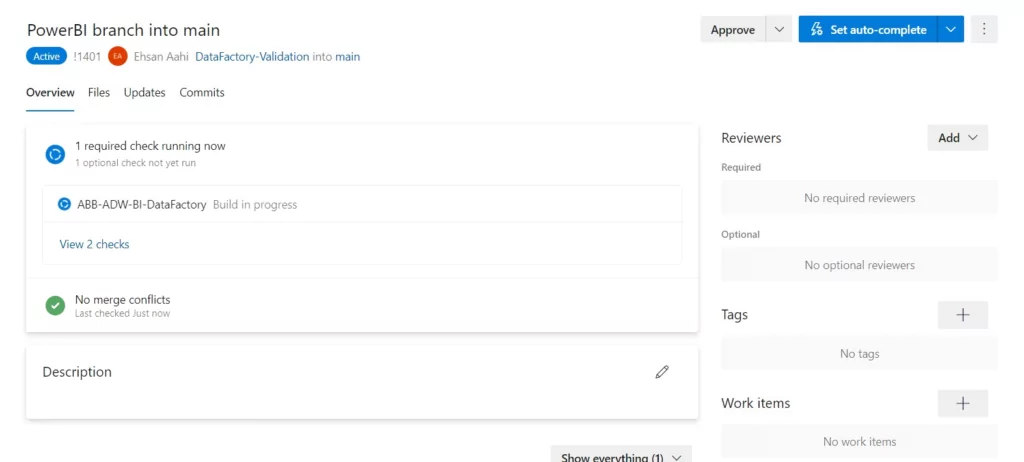
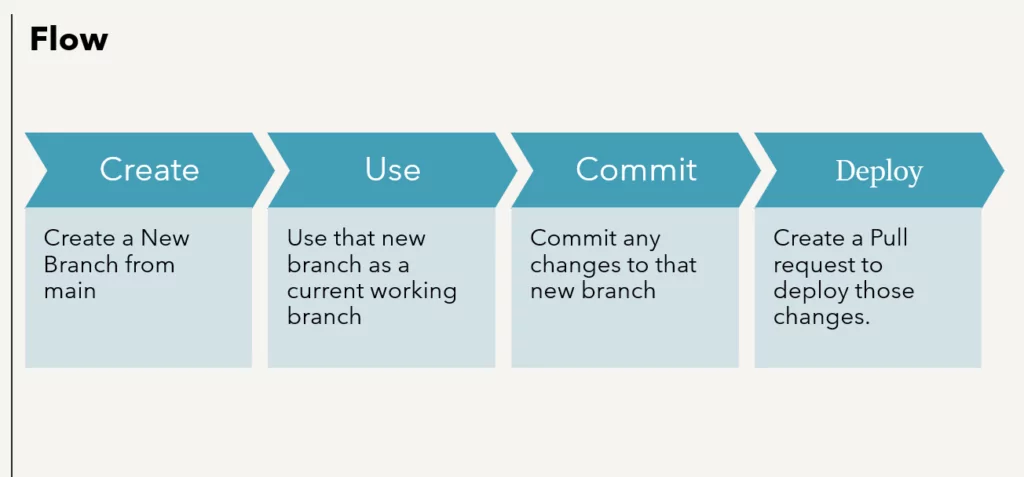
Let’slearn how to create the Build and Release pipelines to automate the deployments for the Data factory.
Build Pipeline
The Data factorybuild pipeline has two stages: PR validation and Arm Templates generationand publishing.
PR Validation
PR validation runs when there is a pull request for the main branch. During validation, the resources of the Data factory will be validated, just like we do from the portal side using the ‘Validate All’ option.
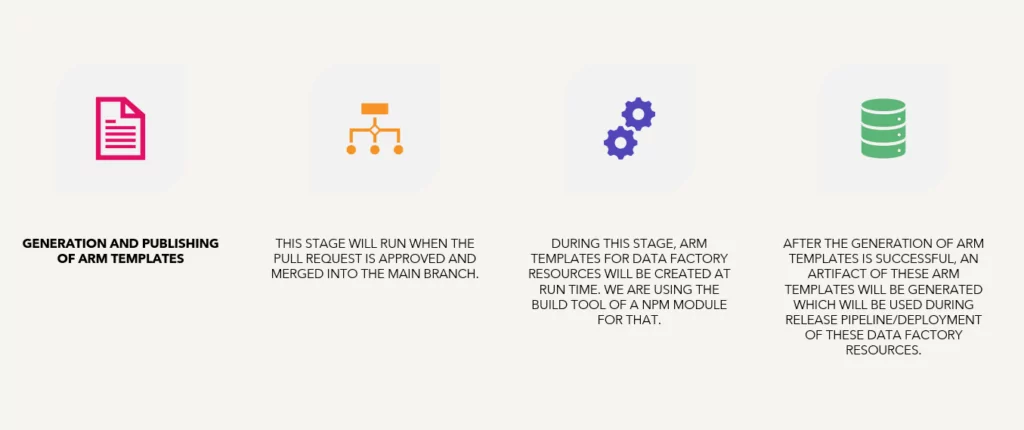
Generation and Publishing of Arm Templates
This stage will run when the pull request is approved and merged into the main branch.
Arm Templates for Data Factory resources will be created at runtime during this stage. After the generation of Arm templates is successful, an artifact of these Arm templates will be generated, which will be used during the release pipeline/deployment of these data factory resources.
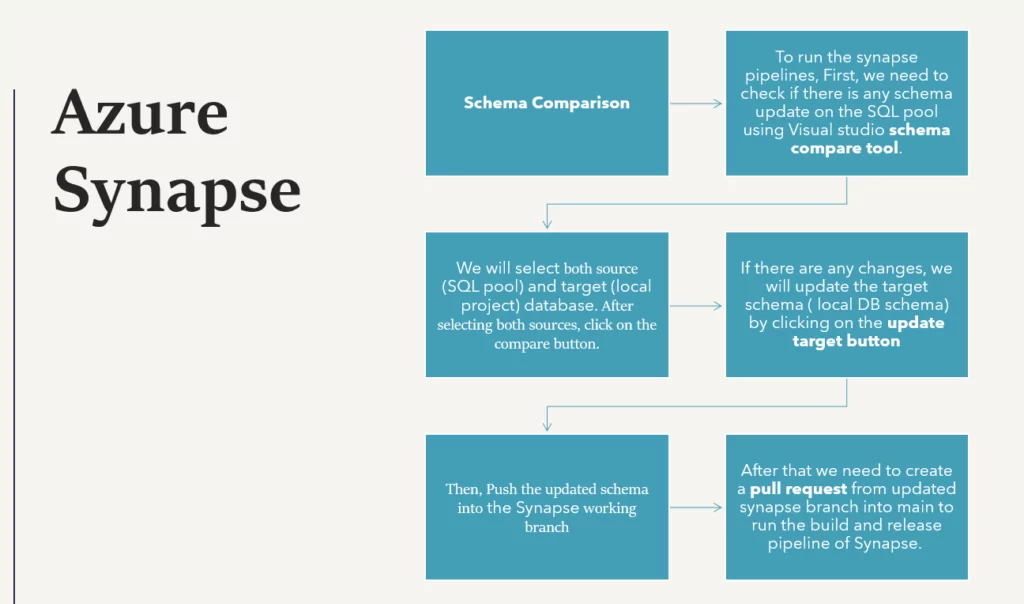
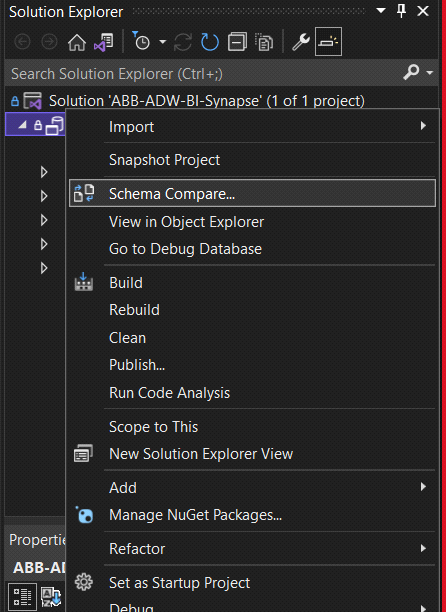
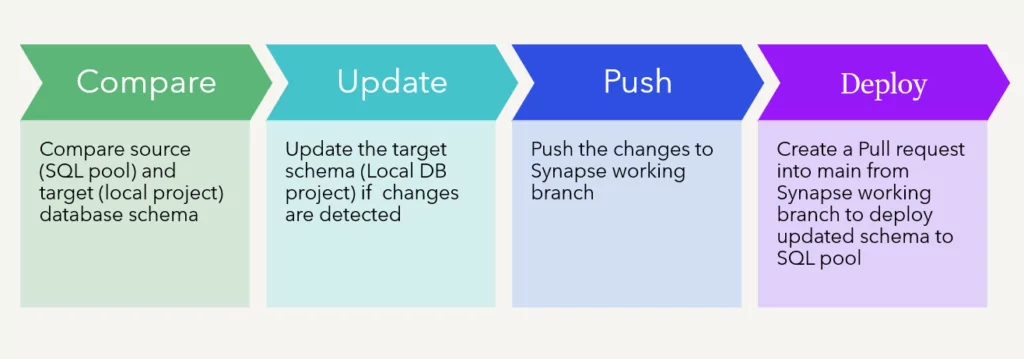
To run the synapse deployment pipeline, first, we need to check for any schema update on the SQL pool using the Visual Studio schema compare tool.
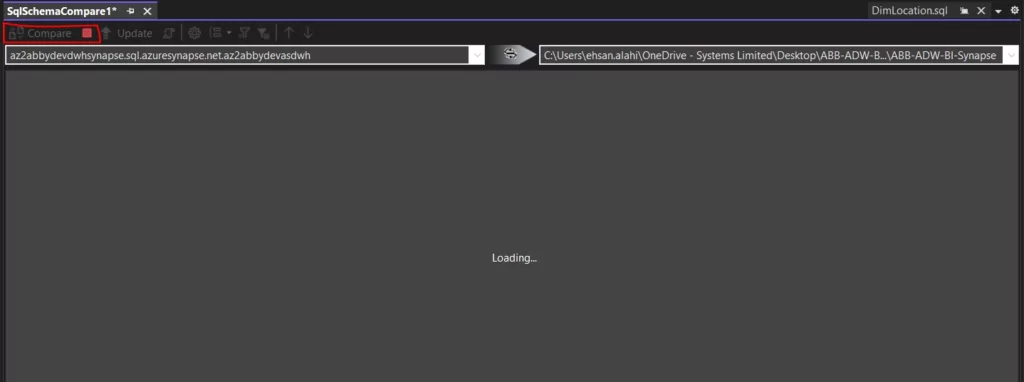
We will select the source (SQL pool) and target (local project) databases. After choosing both sources, click on the compare button.
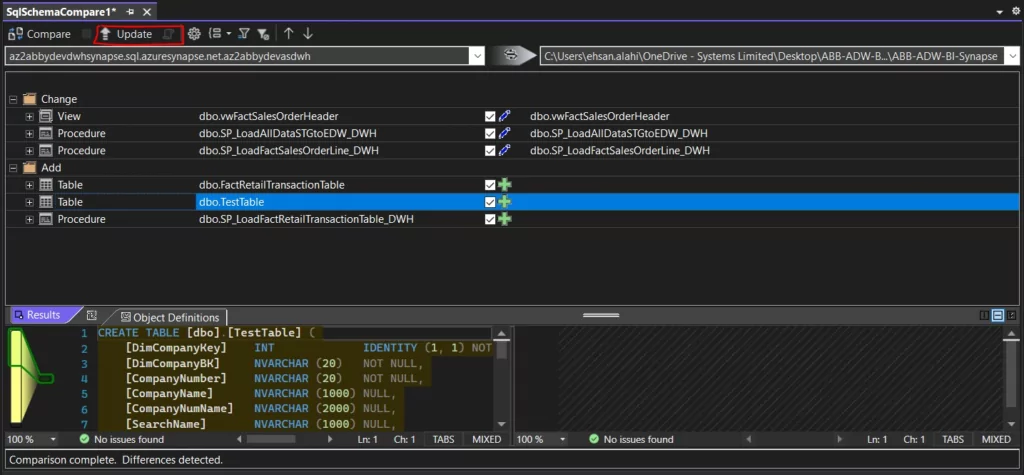
If there are any changes, we will update the target schema (which will be the local DB schema in our case) by clicking on the update target button and then pushing it to the Synapse master branch.
Afterthat,wemustcreateapullrequestfromtheupdatedSynapsebranchintothe maintorunSynapse’s build and release pipeline.
Looking for Azure DevOps Services?
Achieve more with AlphaBOLD Azure DevOps services.
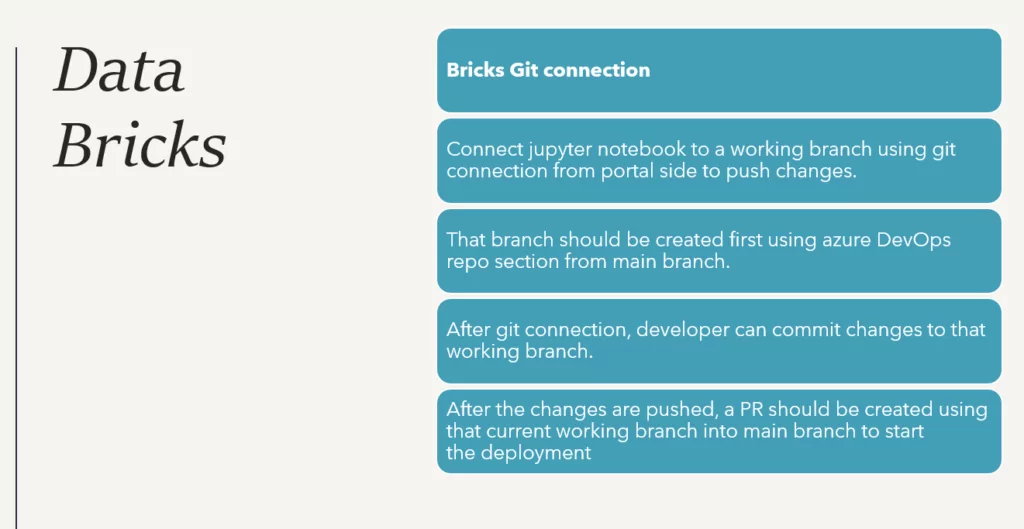
We need to connect the Jupyter Notebook to git using the git connection from the portal side to push changes to the Azure repo. It should be done for each Jupyter notebook.
After pushing the changes, create a PR from the current development branch into the main branch. All of this can be done from the bricks portal, as attached in the screenshots below.
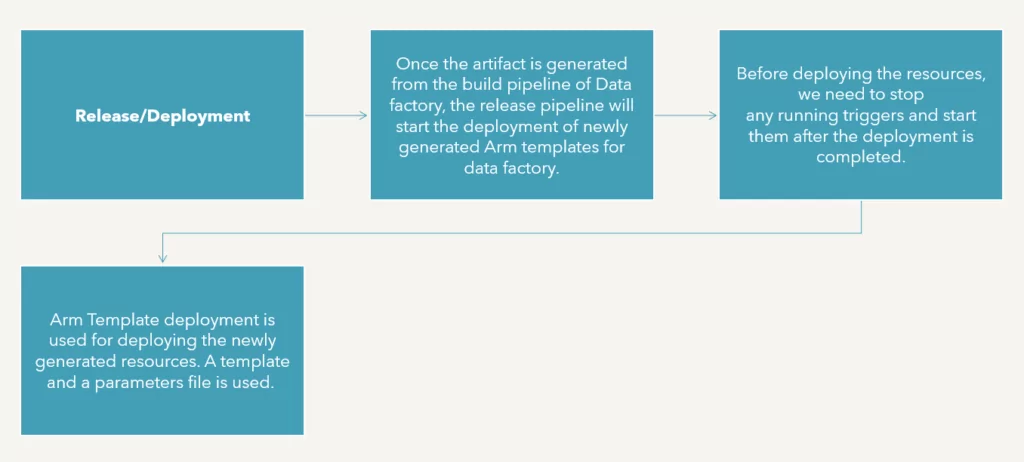
Deployment / Release
Once the PR created above is approved, the release will start deploying updated brick resources like notebooks to the current environment data bricks resource.
Conclusion: Unlocking Business Success with DataDevOps and Azure Integration
In conclusion, the integration of DataDevOps with Microsoft Azure, as outlined in the provided content, represents a crucial step towards aligning business strategies with technical adaptability in today’s dynamic digital landscape. By seamlessly merging data-driven business objectives with agile data solutions, DataDevOps streamlines data workflows and facilitates rapid decision-making. The utilization of DataDevOps on Azure empowers organizations to enhance their time-to-market, make informed decisions, and gain a competitive advantage in the realm of big data and analytics. The strategic insights and practical guidelines presented in this content serve as a valuable resource for business leaders and implementation teams, showcasing the potential to optimize processes and drive business success through effectively utilizingDataDevOps on the Azure platform.