
Introduction
Announced by Microsoft in 2019, Azure Synapse Analytics is limitless analytics being offered on the Azure Cloud providing data integration, Enterprise Data Warehouse (EDW), and Big Data Analytics capabilities. Microsoft has achieved this by integrating various Azure data services such as Azure Data Factory (ADF) pipelines, integration with Power BI, and Azure Data Lake Gen 2 as Data storage. To understand what is new in Azure Synapse Analytics, we need to know how the landscape of Data Engineering and Data Analytics on Azure looked like before the introduction of Azure Synapse Analytics.
Data Analytics Experience before Azure Synapse Analytics
Before introducing Azure Synapse Analytics, typical Data Engineering work included using Azure Data Factory (ADF) services to design and run data pipelines to ingest and orchestrate data. Once the data was in Azure storage, it could be processed using data processing services such as Azure Databricks. The processed data was then stored in Azure SQL Datawarehouse before it was available for reporting by Data Analysts in Power BI, and for Exploratory Data Analysis (EDA) or prescriptive analysis by Data Scientists using Azure Machine Learning.
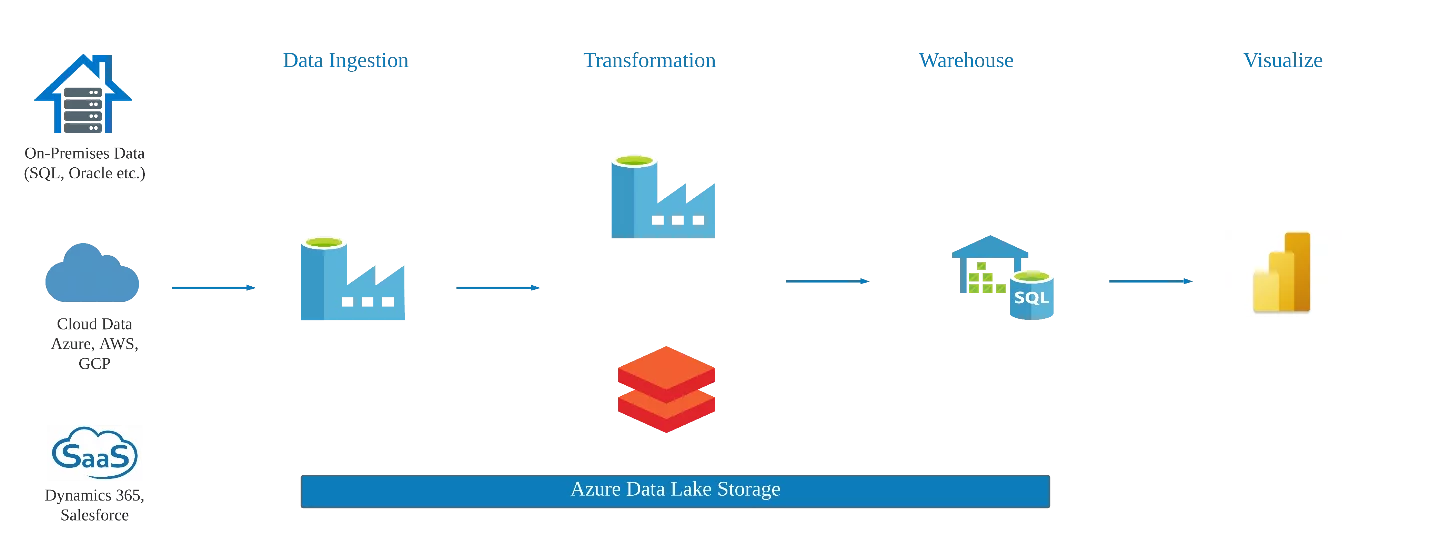
Unified Data Analytics Experience in Azure Synapse Analytics
Azure Synapse Analytics integrated various Azure data services into a single platform, thus allowing cost-effective solutions by replacing the need to manage multiple resources. Using Azure Synapse Analytics, Data Engineers can build data pipelines for ingestion using no-code or low code experiences and query the database using SQL. Data Analysts have access to the Power BI workspace directly from Azure Synapse. Finally, Data Scientists can also perform Big Data Analytics and design Artificial Intelligence solutions due to the integration of Azure Synapse with Azure Machine Learning.

In simpler words, Azure Synapse Analytics brings together the following three components under one service:
- Data integration
- Enterprise data warehouse (EDW)
- Big Data Analytics (BDA)
Let’s look at how each of the above tasks can be achieved using Azure Synapse Analytics.
1. Data integration
It is the process of ingesting data from various sources, orchestrating them, and integrating them into a central repository. Azure Synapse Analytics provides data integration for batch ingestion through Synapse pipelines. It also supports the ingestion of real-time streaming data. Azure Synapse Analytics provides over 90+ data connectors that seamlessly ingest data from various sources to orchestrate and integrate into Azure storage and allow you to write Extract Transform Load (ETL) pipelines all within the Azure Synapse Analytics.
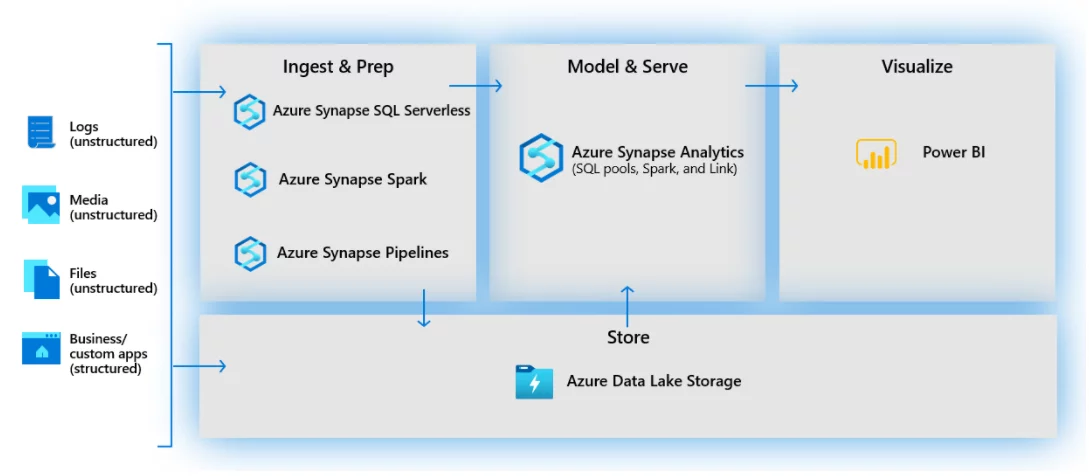
Source: https://docs.microsoft.com/en-us/learn/modules/introduction-azure-synapse-analytics/4-when-use
2. Enterprise data warehouse (EDW)
Azure Synapse Analytics provides all the data warehouse capabilities of Azure SQL Data Warehouse. It provides resources such as Dedicated Synapse SQL Pool or Serverless Synapse SQL pool. We will discuss these resources and their architecture in greater detail later. Apart from Azure SQL Data Warehouse capabilities, it also provides additional capabilities. The EDW provides availability and accessibility to meaningful insights on cross-organizational information which is helpful in effective decision making.
Explore the Power of Azure Synapse Analytics
3. Big data analytics
Big data has high volume, high velocity, and high variety. This data is mostly unstructured. With the increase in big data, the demand for analyzing it is increasing. Azure Synapse Analytics has integrated Data Warehouse capabilities with big data analytics. This integration of data warehouse capabilities with Big Data Analytics is called data lake house. Azure Synapse Analytics allows you to query structured, semi-structured or unstructured data on an Azure Data Lake. The Data Lakehouse provides the liberty of querying the unstructured data that is critical for a business. The traditional DWH was not optimized for unstructured data types, and we had to use Hadoop to extract the required information from unstructured data.
Azure Synapse Analytics’ Architecture
Now that we understand what Azure Synapse Analytics is and what it offers, it is time to look at its overall architecture.

Synapse Analytics Studio
Synapse Analytics Studio is a GUI-based tool that allows a no-code or low-code experience for data ingestion, integration, exploration, warehousing, and Big Data Analytics. It is a one-stop-shop for developers, data engineers, data scientists, and data analysts. Through Synapse Analytics Studio, you can access databases in your storage account and other linked services. You can also write scripts, notebooks, and Power BI reports. You can also create ETL pipelines or Data Flows, and manage jobs, resources, and services.
Azure Data Lake Storage
Azure Synapse Analytics workspace comes with a dedicated Data Lake Storage that allows for a secure, cost-effective, and scalable storage option for all your storage needs and all forms of data (structured, semi-structured, or unstructured). Azure Data Lake Storage is provided in the form of Azure Data Lake Gen 2 that includes all the cost-effective capabilities of Azure Blob storage along with enhancements to performance, management, and security and the addition of hierarchical namespaces. For more details on this, refer to the documentation here: https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-introduction.
Analytics Runtimes
Azure Synapse Analytics provides two main analytic runtimes. These are SQL pools as a part of the Structured Query Language (SQL) engine and Spark pools as Apache Spark on Azure. Additionally, the SQL pool can be dedicated or on-demand. Let’s look at these in more detail.
Azure Synapse Dedicated SQL Pool
SQL Pool has a scale-out architecture with one control node that runs a Massive Parallel Processing (MPP) engine and multiple compute nodes that allow for distributed computing. The dedicated SQL pool provisions dedicated resources and follows the Data Warehouse Unit (DWU) as the unit of scale inherited from Azure SQL Data Warehouse. Once a user runs a T-SQL command, it uses the compute node as a single entry-point, and the workload is then distributed among the compute nodes.
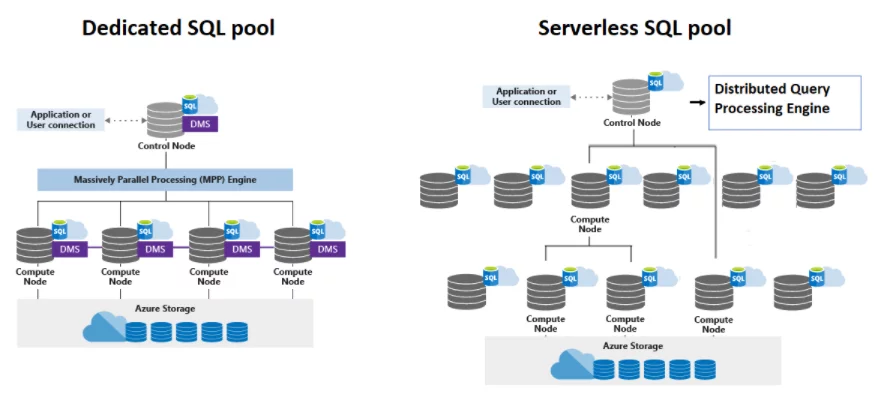
Source: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/overview-architecture
Azure Synapse Serverless SQL Pool
SQL On-Demand pool does not allocate dedicated resources. Instead, it follows a serverless approach. Also, it uses Distributed Query Processing (DPQ) instead of Massively Parallel Processing (MPP) engine. However, like a dedicated SQL pool, it also has one control node, and various computer nodes. SQL serverless can scale on-demand, which allows for the processing of big data. Moreover, as there are no dedicated resources provisioned here, there is no concept of DWU. Instead, the cost is based on the size of the data processed by your query.
Explore Azure DevOps Excellence
Apache Spark in Azure Synapse Analytics
Apache Spark is the de-facto standard of parallel processing frameworks in big data analytics. It allows for fast, in-memory, parallel processing. Synapse Spark serverless is Apache Spark on the Azure platform. As the name suggests, it also provides a serverless computer. Every Azure Synapse workspace has a pre-built Spark engine and notebook support that supports Python, Scala, C#, and SQL. Spark pools can be shared among different users. However, each user must have its Spark instance.
Conclusion
What’s new in Azure Synapse Analytics? We know that it combines data integration, data warehouse, and big data analytics services on Azure. We also looked at the high-level architecture of Azure Synapse Analytics. We looked at Synapse Studio, Azure Data Lake storage, dedicated SQL pool, Serverless SQL pool, and Synapse Spark. In the next blog, we will look at the complete architecture of the dedicated SQL, SQL Serverless and Synapse Spark as they are the most critical components of Azure Synapse Analytics.