

Introduction
If you come from a relational database background, the general hierarchy of the resources is that you have a server that can host multiple databases. Inside those databases, there can be multiple tables which are comprised of rows and columns that actually persist data. You can segregate your data into separate databases according to the business model and implement security at different levels of the hierarchy. Keep this resource model in mind as a reference to understand how Cosmos DB stores data.
Learn more about: Introduction to Azure Cosmos DB
There are four generic resource types for an Azure Cosmos DB:
- Azure Cosmos DB Account
- Databases
- Containers
- Items
They can be realized differently depending upon the type of API used for the Cosmos DB Account. The hierarchy of these resources goes as such:
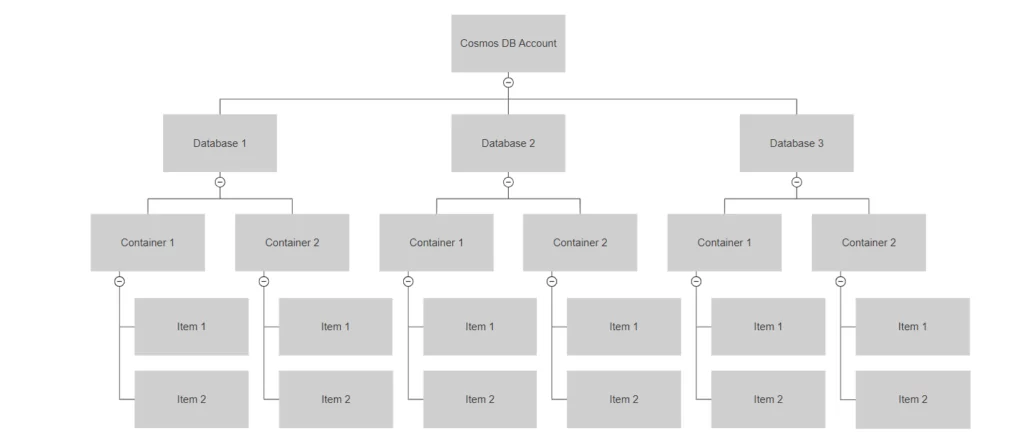
1. Azure Cosmos DB Account
In traditional database systems, multiple databases can reside inside a single server. This server is the access point to these databases. If the databases are performing poorly, we have an option to scale up the server. However, there is no concept of a server in the PaaS cloud, at least not a physical one. The storage and compute are virtualized and presented as such. Hence, we need an access point to the databases other than connecting to a server. Azure Cosmos DB Account provides this access point to connect to the databases through a unique DNS name. Also, you can increase or decrease the throughput of your databases through the Cosmos DB Account, along with geo-replicating databases for high availability.
Read More: Azure Cosmos DB – The Ultimate Guide
2. Databases
Inside an Azure Cosmos DB account, you can create multiple databases for any API supported by Cosmos DB. Just like traditional systems, you can isolate your databases according to the business model. For example, you can have a Sales database, a Marketing database, and a Payroll Database for Sales, Marketing, and HR personnel, respectively. With a proper security model in place, none of these user groups will be able to access each other’s data. Apart from security, we can isolate stored procedures and functions to implement different business logic for each of them. Also, you scale each database separately to provision different levels of throughput.
There are some caveats when creating databases in Cosmos DB.
- All the API containers use databases of one kind or another, except for Table API. When we create tables for Table API, a default database ‘TablesDB’ is created, and all the tables reside in this database. We can’t create a new database or rename it.
- Also, the name ‘Database’ is not used for the Cassandra API. Instead, it uses ‘Keyspace,’ which is native to Cassandra itself.
Maximize the Potential of Azure with AlphaBOLD
Unlock the full capabilities of Azure and harness its power for your business needs. Partner with AlphaBOLD to customize your resource model and drive efficiency. Let's Optimize Together.
Request a Demo3. Containers
At first sight, containers seem to be just ordinary database tables, but that would be a huge understatement. Apart from the multiple shapes they can take for each API, containers are partitioned horizontally based on a shared key, which is mandatory when creating the container. The sharding of data into multiple partitions increases the performance of containers manifold. Also, you can configure Time-To-Live (TTL) on Containers so that expired records can be deleted after a specific amount of time.
An Azure Cosmos DB Container can take multiple shapes depending upon the API:
1. SQL API:
When opting for SQL API, Cosmos DB provides us with a Container in which we can store documents. You can directly create and execute a SQL query from Azure Portal UI to query data in this container. Containers, along with Graphs, also enable server-side implementation through:
- Stored Procedures
- User-Defined Functions
- Triggers
Read More:
2. Cassandra API:
Cassandra uses Tables to stores rows of data. As mentioned in the previous article, these tables are wide-column that bridge the gap between inflexible relational tables and schema-less NoSQL tables. Cassandra Tables don’t have any support for server-side implementation; however, the tables can be queried through CQL language both from the API and the UI itself.
3. MongoDB API:
MongoDB API uses a Collection to store BSON documents. Azure Cosmos DB provides a Shell to run MongoDB commands to query documents from the Azure Portal UI. The main difference between the storage model of MongoDB API and SQL API is that MongoDB API doesn’t have any support for server-side implementation.
4. Gremlin API:
All Cosmos DB Containers are similar to each other in terms of storage as they use a table of one kind or another. However, Gremlin API uses Graph to store vertices and edges. Graph containers are different in the sense that they not only store the entities but also the relationship between them. Despite the difference, Graph containers have the support to implement server-side functionality.
5. Table API:
As the name suggests, Table API uses Tables to store key-value data. It originated from Azure Table Storage but was merged into Cosmos DB in 2017. The tables should have a Partition Key and a Row Key value for each row in the table. Partition Key helps in partitioning the data horizontally for better scalability, and Row Key helps in identifying a single row in the table.
Transform your Data Management Strategy with AlphaBOLD
Ready to revolutionize your data management approach with Azure? Take the first step towards seamless integration and enhanced performance by contacting AlphaBOLD today. Explore Our Solutions!
Request a Demo4. Items
Since Cosmos DB supports multiple types of containers, the items stored in these containers are also different:
| API | SQL | Cassandra | MongoDB | Gremlin | Table |
|---|---|---|---|---|---|
|
Container |
Container |
Table |
Collection |
Graph |
Table |
|
Item |
JSON Document |
Row |
BSON Document |
Vertex or Edge |
Item |
Although the Items differ substantially from each other, they are all stored in the same way using the ARS model described in the previous article. This property of Cosmos DB to save these different types of data in the same format will be a huge plus if we can query them interchangeably.
Read More: Consistency Model of Azure Cosmos DB
Conclusion
In this article, we went through the resource model of Cosmos DB and discussed how it differs from the traditional on-prem model. Also, we looked at different types of containers and items supported by Cosmos DB and how we can query them.
Thank you for bearing with me through all the theory. It was necessary to grasp the basics of Cosmos DB. In the next article, we will finally dive into some hands-on labs to see how it all connects. Let the good stuff begin!
If you have any question or queries, do not hesitate to reach out to us!
Explore Recent Blog Posts






