

Introduction
This blog is the second part of the big data analytics blog series. In this blog, I will explain how to move and store petabytes of semi-structured data files using Microsoft Azure cloud services. Primarily we will discuss the underlying architecture of the services involved in this process and then explain how to configure it for the problem described in the previous blog.
Data movement
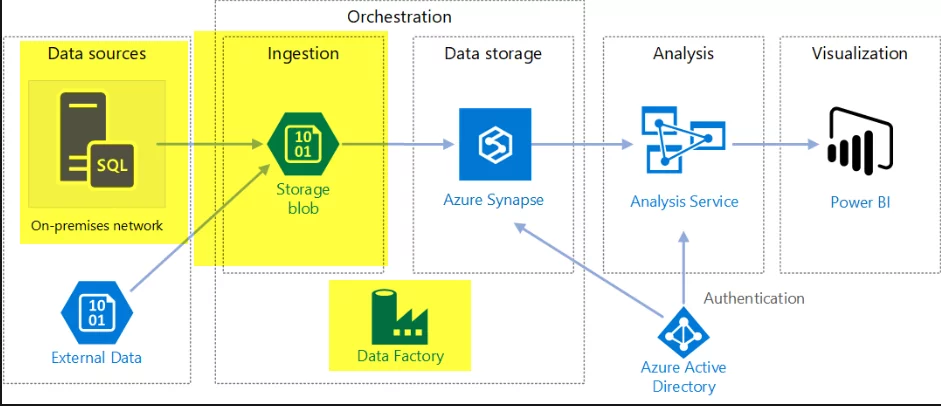
In the business scenario covered in the previous blog, we have data in our on-prem SAN drives. The challenge is to move data from the SAN drives to the cloud storage, which should also be optimized for further data processing. Microsoft has designed the Azure Storage account to solve such data storage problems and to move data periodically from on-premises to Azure Storage account. I will use the Azure Data Factory to implement this scheduled data movement.
Azure Data Factory
Azure Data Factory provides data movement services across a variety of data stores. Azure Data Factory also has a built-in feature for securely moving data between on-premise locations and cloud. It helps in data ingestion, movement, and publishing needs for your big data and advanced analytics scenarios.
When moving data to/from an on-premises data source, a data gateway is used. Data management gateway is a software you can install on-premises to enable data pipelines. It manages access to the on-premises data securely and allows seamless data movement between on-premises data sources.
Now, we will ingest data into the Azure Storage account using Azure Data Factory.
So, lets quickly discuss the architecture of Azure Storage account and Azure Data factory before we move forward with the implementation of Data ingestion.
Azure Storage Account: (Azure Data Lake Gen 2)
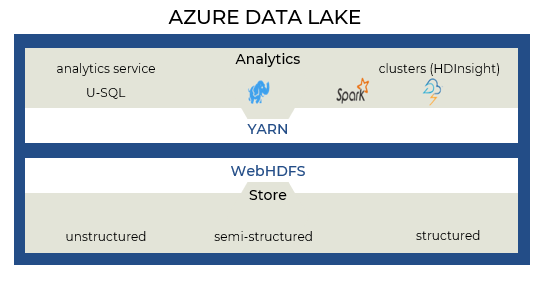
Let’s talk about the Azure Storage Account first. It is important to familiarize with the Data Lake Gen 1 service to understand the Azure Data storage account and Azure Data Lake Gen 2.
Data Lake Storage Gen1 is an Apache Hadoop Azure cloud file system that works with the Hadoop Distributed File System (HDFS) and the Hadoop ecosystem.
It provides limitless storage and can store a variety of analytics data. Additionally, it imposes no limitations on account sizes, file sizes, or the amount of data stored in a data lake.
We can also perform USQL, Spark, and HD Insights jobs on Azure Data Lake Gen 1 for data massaging using the YARN platform. In a nutshell, these jobs/services are used to process, clean, and shape the unstructured data, which could be XML or delimited CSV files.
Now that you know the gist of Azure Data Lake Gen 1, we can move onto discuss the Azure Storage account service. Well, Azure Storage Account is “sort of” a parent service that supports multiple “sub-services,” and these services are designed for different types of data and use cases.
Azure storage account provides five types of storage services:
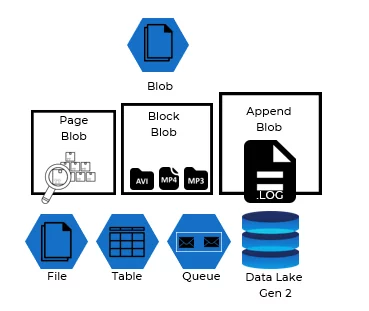
- Blob Service is designed to store large audio, video, text and, any file. It supports Append blob, block blob, and page blob file structures. Each structure is designed for a specific usage of files.
- File Service uses samba protocol and used to keep files for Virtual Machines. For instance, windows VMs running on Azure cloud can share and store their files using File service
- Table Service is no SQL datastore. It can store TBs of tables and entities in JSON like format. It doesn’t enforce a schema on entities
- Queue Service – it keeps the messages in queue format for processing
- Data Lake Gen 2 – For this Big data Solution Data Lake, Gen 2 is the focal point for us, and we will use only this storage account service to host our CSV file. It is the best of the two worlds. It combines functionalities of Data Lake Gen 1 service with BLOB Storage service features. Even though there is no separate service on Azure as Data lake Gen 2, we must enable Data Lake Gen 2 functionalities on BLOB Storage container.
That will help us create namespaces and hierarchical folders inside BLOB Storage containers. It will also enable us to run USQL and spark jobs.
We have learned that Data Lake Gen 2 is just an extension of Azure BLOB storage and similar services. So, when to use Data Lake Gen2 vs. BLOB storage. As per Microsoft both these services are interchangeable and behave the same in the EDWH process. Blob Storage service is good for non-text-based files like database backups, photos, videos, and audio files. On the other hand, the data lake is better at large volumes of text data.
Data Lake Gen 2 Pricing
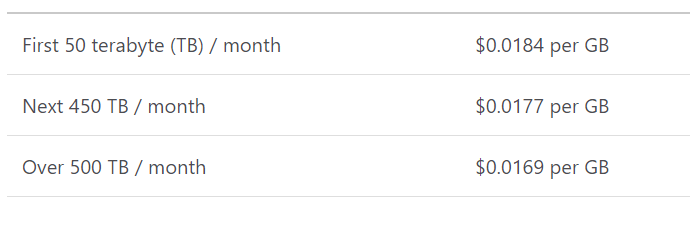
Data Storage Price:
Read/Write Operations Cost:

How billing works?
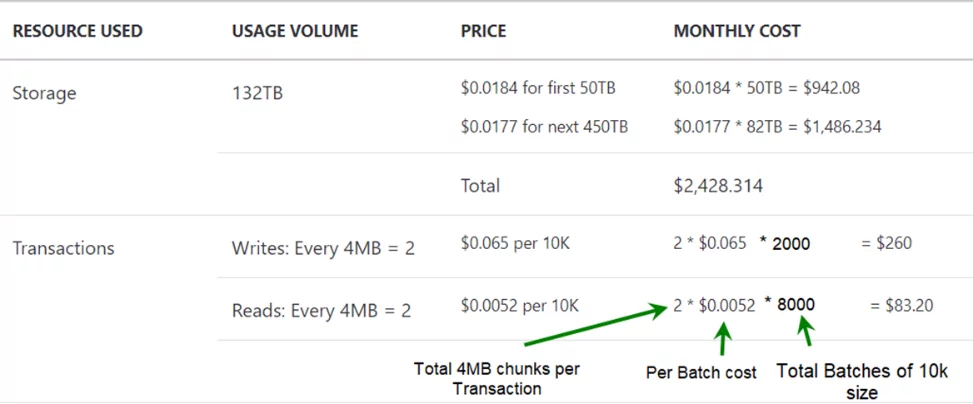
If we have total file size of 132 TB and have performed 100 million operations of size 6MB on it and 80% were Read operations, then we will be charged with $2,771 per month.
Total Storage Size of files = 132 TB (first 50 + next 82)
Operations performed =100 million
Write Operations = 20 million
Read Operations =80 million
Size of each operation = 6MB for single operation (4MB + 2MB = 6 MB) Microsoft will charge for two transaction for a single operation.
Data Ingestion
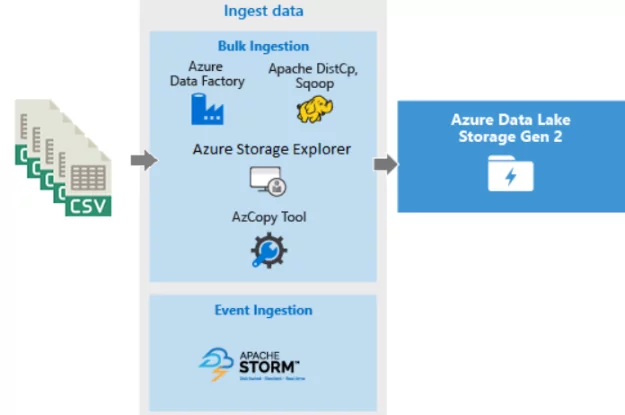
So far, we have learned about Azure Data Factory and Azure Storage Account (Data Lake Gen 2) and how these two services can solve the problem of data movement and ingestion. Now, I am going to list the steps to configure these services:
Step 1: Create Azure account and create a new instance of Data factory V2.
Step 2: Create Azure Storage account and enable Data Lake Gen 2 features under Advanced options and create a BLOB container to host CSV files.
Step 3: Create a “Copy data” activity in the Azure Data Factory.
Step 4: Select the File System as a source and Azure Data Lake Storage Gen 2 as a Sink.
Optional 1: we can also use AzCopy tool to move data from the file system to Azure Data Lake Storage.
https://docs.microsoft.com/en-us/azure/storage/common/storage-use-azcopy-v10
Optional 2: We can use Azure Storage Explorer to upload files from the file system to Azure Data Lake Storage Gen 2.
https://azure.microsoft.com/en-us/features/storage-explorer/
Summary
In this blog post, we have discussed the Azure Storage Account and Data Lake Gen 2 Storage service. We also have discussed how Azure Data Factory/ Azure Storage Explorer / AzCopy Tool can help us to move Terabytes of data from File Server to Azure Data Lake Gen 2 service. These services combined, help us solve the Big data ingestion problem. In the next blog, I will explain how to perform data orchestration in Azure Synapse. Stay tuned!
Big Data Analytics on Machine Generated Data Using Azure Data Platform and Power BI (Part 1)