Introduction
This blog is the third part of the Big Data Analytics blog series. In this blog, I will explain how to move data from Azure Data Lake Gen 2 to Azure Synapse for data orchestration using the ELT process. We will learn about Polybase, External tables, Architecture of Azure Synapse, and Licensing model. Data orchestration in cloud data warehousing is one of the most challenging jobs as the success of this step decides the performance of the complete solution.
Data Orchestration
At this stage, we have data in Azure Data Lake Gen 2 BLOB containers in the form of semi-structured CSV files. ADL Gen 2 is best for storing and cleansing of the data. However, it is not designed to run heavy and complex queries to get analytical answers from data. We can directly connect Power BI with ADL Gen 2 to solve this problem, but this would cause the performance to be very poor. Therefore, we need to convert this semi-structured data to structured data to ensure better performance for relational queries. We will use Azure Synapse for cloud data warehousing.
Azure Synapse (Formerly Azure DWH)
Azure Synapse is a limitless analytics service that brings enterprise data warehousing and Big Data Analytics together. it has Massive Parallel Processing Engine that is responsible for query distribution, which is the most powerful feature of Synapse
The Architecture of the Azure Synapse
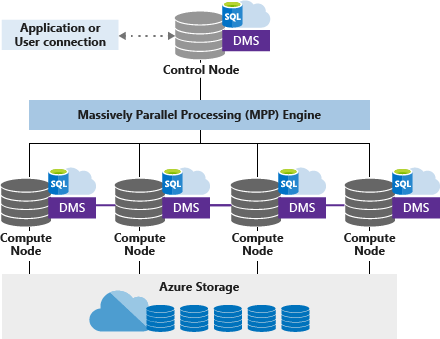
Control node
Azure Synapse has only one control node. Applications directly connect with the control node and issues T-SQL commands, which is the single point of entry for all applications. The Control node operates the MPP engine, which then optimizes queries for parallel processing, and then transfers the operations to Compute nodes that work in parallel.
Compute Node(s)
Consider a compute node as a SQL server instance. All instances are working together in parallel to solve one query. Each compute node is also responsible for storing data in the storage account. We can choose several compute nodes that range from 1 to max 60 nodes. The numbers depend on the DWU level selected. We can also call it “SQL pool”. In the diagram mentioned above, we have DWU 400, and Microsoft has assigned 4 compute nodes to the SQL pool.
DMS
Microsoft defines Data Movement Service (DMS) as “the data transport technology that coordinates data movement between the compute nodes.” For instance, some queries require data movement to ensure the parallel queries return accurate results. DMS ensures that the right data gets to the right location or right Compute node at the right time.
Azure Storage
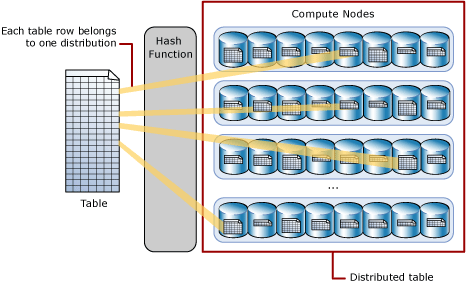
Azure synapse stores its data in Azure Storage Service, and obviously, it has separate charges from computing. The basic building block of Azure Storage is the distribution unit by default. Azure Synapse has predefined 60 distributions inside Azure Storage Account, and we cannot change this number.
Distribution is a storage location or segment inside the storage account. Compute nodes are mapped to distributions. In a nutshell, if we have 60 compute nodes, then each compute node will be associated with single distribution, and if we have 1 compute node, then it will be mapped to all 60 distributions.
Data storage in distributions using the HASH function
Polybase and External Tables
Before explaining the external tables, it is important to discuss Polybase. We can consider Polybase as a generic data connector for Azure Synapse to fetch data from ADL Gen 2 and other heterogeneous sources. We can use it to source data from ADL, Hadoop, Azure Storage Account, No-SQL databases, and even from open database connectivity.
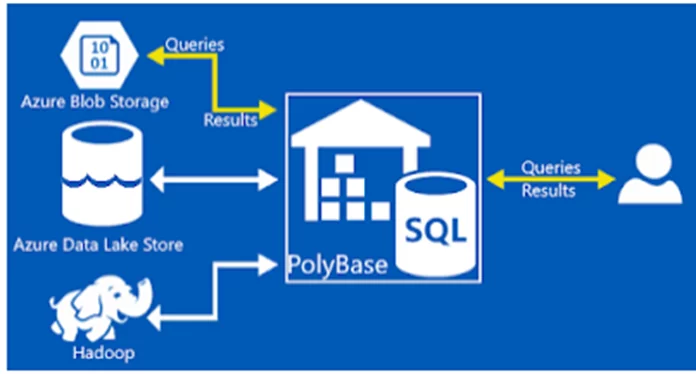
The External tables we create in Azure Synapse using Polybase are only stubs. They do not contain actual data. Instead, External tables give us the power to run SQL queries on semi-structured data hosted on external sources like ADL Gen 2.
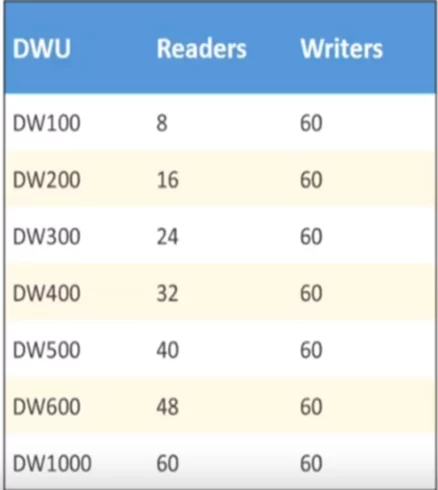
In Azure Synapse, we can increase or decrease the read/write power of Polybase. Each DWU unit in Azure synapse has dedicated Read/write headers for Polybase connectivity.
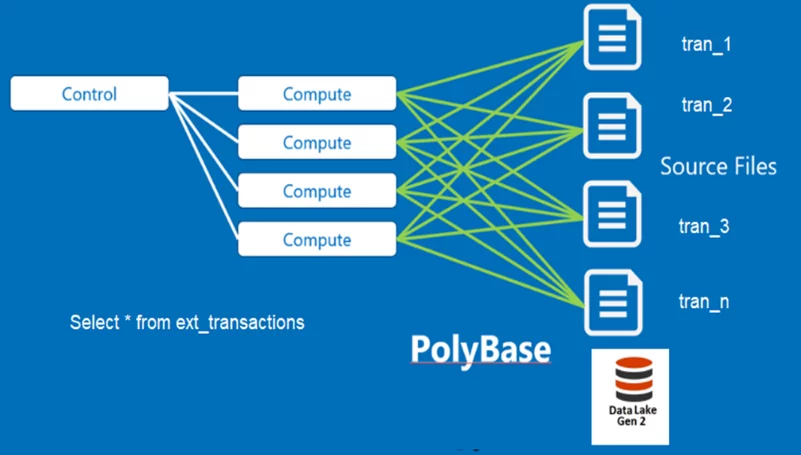
Let’s, take an example; we have thousands of transaction files hosted on Azure Data lake Gen 2 and external table in Azure synapse for Transactions.
If we are using DWU400, then we have 32 readers to read 32 files in parallel at a time as one reader is associated with only one file. The more the readers, the better response time we will get in reading data from the external system.
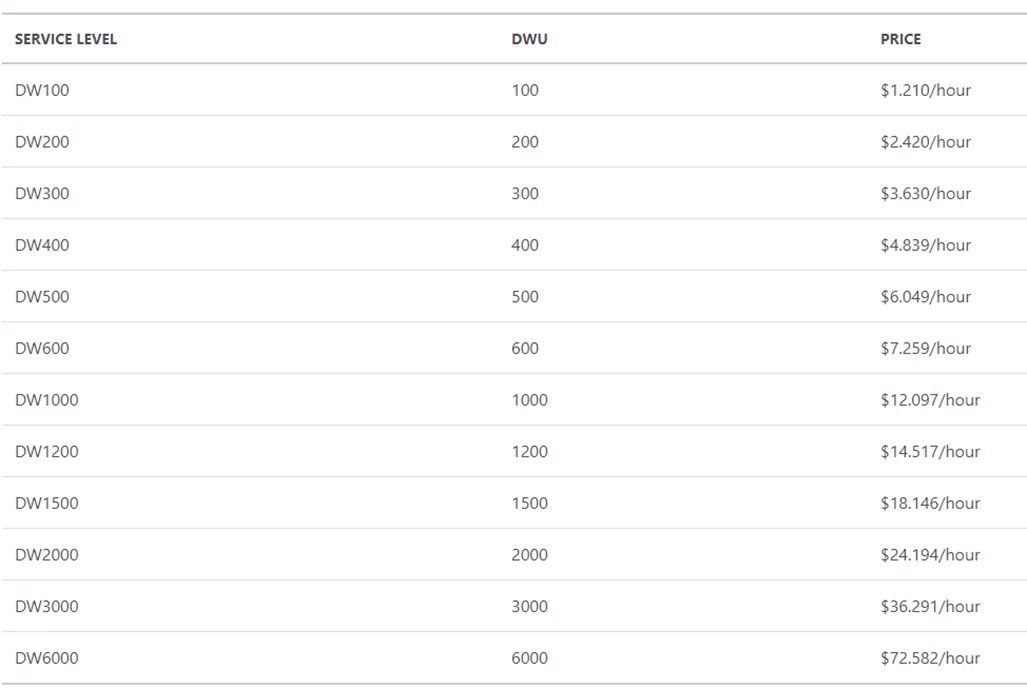
Azure Synapse Billing
The billing model for Azure Synapse compute, and storage is simple. For the compute model, we must pay hourly based on the DW level selected, and for the storage model, the price is 122.88 per 1 TB per month.
Cloud Data Warehousing Process: ELT
By the time we reach this stage, we are aware of the overall Enterprise Data warehousing model and know all the components of Azure Synapse. We can easily build Stage tables and DWH tables that could serve Power BI for Analytics.
Step 1: Create External tables using Polybase in Azure Synapse (these tables should point to the data files folder in Azure Data Lake Gen 2)
CREATE EXTERNAL TABLE (Transact-SQL) – SQL Server
Step 2: Load Azure Synapse stage tables by using External tables and T-SQL. Remember to always create a Round Robin distribution for Stage tables. Perform transformations required by the workload while the data is in the Staging table before moving the data in the production table.
Load New York Taxicab data – Azure Synapse Analytics
Step 3: Now, we have the data in a structured table format. We can use SSIS/Data Factory or custom stored procedures to populate our data warehouse table from the stage tables.
Instead of ETL, design ELT – Azure Synapse Analytics
For this use case, we have created two fact tables with different granularity. In the Detail Fact table, we have 15 minutes interval data, and the total number of rows in the table are 43.2 Billion. In the Summary Fact table, we have the day level granularity of data, and all the data rolled up to the day level that reduced the 43.2 Billion rows to 700 million rows.
Summary
In this blog post, we have discussed Azure Synapse and its components, primarily External Tables and Polybase. So far, we have built EDWH tables in Azure Synapse, and these tables will be used for Power BI Analytics. In the next blog, I will explain how to build lighting fast Power BI reports on billions of rows. Stay tuned!
Big Data Analytics on Machine Generated Data Using Azure Data Platform and Power BI (Part 1)




