
Contents
- INTRODUCTION
- BIG DATA ANALYTICS ON MACHINE GENERATED DATA USING AZURE DATA PLATFORM AND POWER BI
- Why Big Data Analytics Is Important For Your Organization?
- Benefits
- DATA MOVEMENT AND STORAGE
- Azure Data Factory
- Azure Storage Account: (Azure Data Lake Gen 2)
- DATA ORCHESTRATION
- The Architecture of The Azure Synapse
- CONTROL NODE
- COMPUTE NODE(S)
- DMS
- AZURE STORAGE
- Data storage in distributions using the HASH function
- POLYBASE AND EXTERNAL TABLES
- BIG DATA ANALYTICS
- POWER BI AGG TABLES FOR BIG DATA ANALYTICS
Introduction
In today’s corporate landscape, businesses are looking to secure their future by enhancing the analytical capabilities that will help them build and scale their operations. To do so, companies are exploring big data infrastructure to support these new endeavors in a timely and cost-efficient manner.
AlphaBOLD has helped many companies achieve these Big Data capabilities by designing solutions that generate deep insights for efficient response time. AlphaBOLD provides organizations with the following:
BIG DATA ANALYTICS ON MACHINE GENERATED DATA USING AZURE DATA PLATFORM AND POWER BI
Big data analytics examines enormous amounts of data to uncover hidden patterns and to find business insights. In this blog series, we will talk about running analytics on petabytes of data using a big data solution capable of handling large scale data. One important aspect of any big data project is unstoppable data growth. Solution architects need to take this into consideration to build solutions that scale. In this post, we will cover how to build a solution that could scale and handle enormous amounts of data. The platform that we have chosen to demonstrate this capability ensures that the solution’s performance will not be impacted even on petabytes of data.
Why Big Data Analytics Is Important For Your Organization?
Most of the companies have terabytes of data. Designing big data solutions only for the initial load is not the only important phase. Big data solution architects should also ensure that the solution will perform and run analytics on growing data in the future.
Benefits:
Once we decide on the best architecture and data platform for our big data solution, we can focus on its benefits:
- Cost reduction: When it comes to managing big data, using traditional methods is costly as compared to purpose-built big data technologies such as Hadoop or cloud-based analytics such as Azure. These services and platforms bring significant cost advantages when it comes to storing enormous amounts of data.
- Faster and better decision-making: Hadoop, Azure data platform, and in-memory analytics empower companies with speed and the ability to analyze new data sources. This allows businesses to make better, time-efficient decisions.
- New products and services: Big data analytics helps us to gauge customer needs or performance of sensors. This can also be used to identify what new products and services are required in specific areas and at what time.
To learn more about the benefits of Big Data Analytics and to read a first-hand Big Data case study, click here.
DATA MOVEMENT AND STORAGE
In the business scenario covered in the blog mentioned above, we have data in our on-prem SAN drives. The challenge is to move data from the SAN drives to the cloud storage, which should also be optimized for further data processing. Microsoft has designed the Azure Storage account to solve such data storage problems and to move data periodically from on-premises to Azure Storage account. I will use the Azure Data Factory to implement this scheduled data movement.
Azure Data Factory
Azure Data Factory provides data movement services across a variety of data stores. Azure Data Factory also has a built-in feature for securely moving data between on-premise locations and cloud. It helps in data ingestion, movement, and publishing needs for your big data and advanced analytics scenarios.
When moving data to/from an on-premises data source, a data gateway is used. Data management gateway is a software you can install on-premises to enable data pipelines. It manages access to the on-premises data securely and allows seamless data movement between on-premises data sources.
Now, we will ingest data into the Azure Storage account using Azure Data Factory.
So, let’s quickly discuss the architecture of the Azure Storage account and Azure Data factory before we move forward with the implementation of Data ingestion.
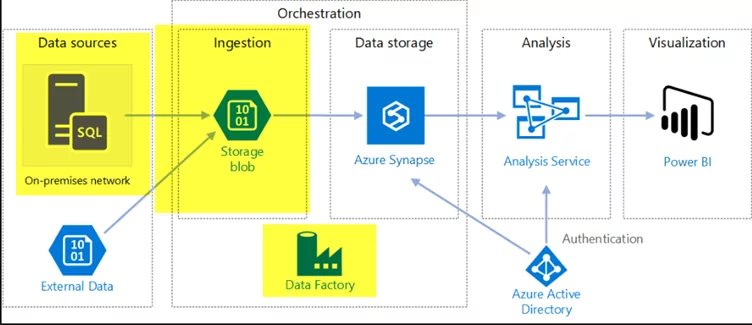
Azure Storage Account: (Azure Data Lake Gen 2)
Let’s talk about the Azure Storage Account first. It is important to familiarize yourself with the Data Lake Gen 1 service to understand the Azure Data storage account and Azure Data Lake Gen 2.
Data Lake Storage Gen1 is an Apache Hadoop Azure cloud file system that works with the Hadoop Distributed File System (HDFS) and the Hadoop ecosystem.
It provides limitless storage and can store a variety of analytics data. Additionally, it imposes no limitations on account sizes, file sizes, or the amount of data stored in a data lake.
We can also perform USQL, Spark, and HD Insights jobs on Azure Data Lake Gen 1 for data massaging using the YARN platform. In a nutshell, these jobs/services are used to process, clean, and shape the unstructured data, which could be XML or delimited CSV files.
For information on the Azure Storage account service, click here.
DATA ORCHESTRATION
At this stage, we have data in Azure Data Lake Gen 2 BLOB containers in the form of semi-structured CSV files. ADL Gen 2 is best for storing and cleansing the data. However, it is not designed to run heavy and complex queries to get analytical answers from data. We can directly connect Power BI with ADL Gen 2 to solve this problem, but this would cause the performance to be very poor. Therefore, we need to convert this semi-structured data to structured data to ensure better performance for relational queries. We will use Azure Synapse for cloud data warehousing.
Azure Synapse (Formerly Azure DWH)
Azure Synapse is a limitless analytics service that brings enterprise data warehousing and Big Data Analytics together. It has a Massive Parallel Processing Engine that is responsible for query distribution, which is the most powerful feature of Synapse.
The Architecture of The Azure Synapse
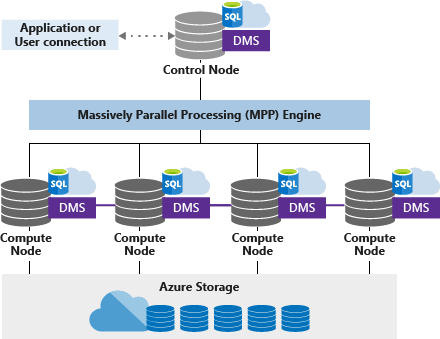
CONTROL NODE
Azure Synapse has only one control node. Applications directly connect with the control node and issue T-SQL commands, which is the single point of entry for all applications. The Control node operates the MPP engine, which then optimizes queries for parallel processing, and then transfers the operations to Compute nodes that work in parallel.
COMPUTE NODE(S)
Consider a compute node as a SQL server instance. All instances are working together in parallel to solve one query. Each compute node is also responsible for storing data in the storage account. We can choose several compute nodes that range from 1 to max 60 nodes. The numbers depend on the DWU level selected. We can also call it “SQL pool.” In the diagram above, we have DWU 400, and Microsoft has assigned 4 compute nodes to the SQL pool.
DMS
Microsoft defines Data Movement Service (DMS) as “the data transport technology that coordinates data movement between the compute nodes.” For instance, some queries require data movement to ensure the parallel queries return accurate results. DMS ensures that the right data gets to the right location or right Compute node at the right time.
AZURE STORAGE
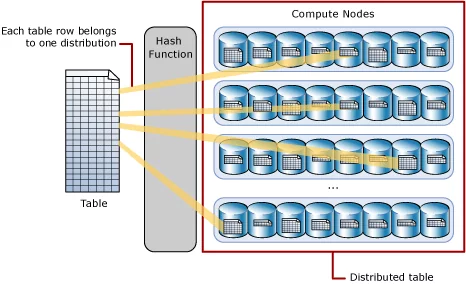
Azure synapse stores its data in Azure Storage Service, and obviously, it has separate charges from computing. The basic building block of Azure Storage is the distribution unit by default. Azure Synapse has predefined 60 distributions inside Azure Storage Account, and we cannot change this number.
Distribution is a storage location or segment inside the storage account. Compute nodes are mapped to distributions. In a nutshell, if we have 60 compute nodes, then each compute node will be associated with single distribution, and if we have 1 compute node, then it will be mapped to all 60 distributions.
Data storage in distributions using the HASH function
POLYBASE AND EXTERNAL TABLES
Before explaining the external tables, it is important to discuss PolyBase. We can consider PolyBase as a generic data connector for Azure Synapse to fetch data from ADL Gen 2 and other heterogeneous sources. We can use it to source data from ADL, Hadoop, Azure Storage Account, No-SQL databases, and even from open database connectivity.
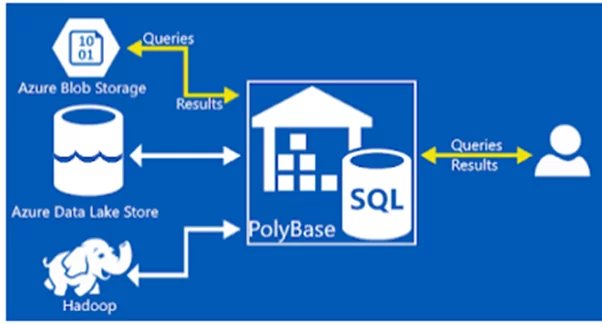
The External tables we create in Azure Synapse using PolyBase are only stubs. They do not contain actual data. Instead, External tables give us the power to run SQL queries on semi-structured data hosted on external sources like ADL Gen 2.
In Azure Synapse, we can increase or decrease the read/write power of PolyBase. Each DWU unit in Azure synapse has dedicated Read/write headers for PolyBase connectivity.
To explore this topic further, and to learn more about Azure Synapse Billing, click here.
BIG DATA ANALYTICS
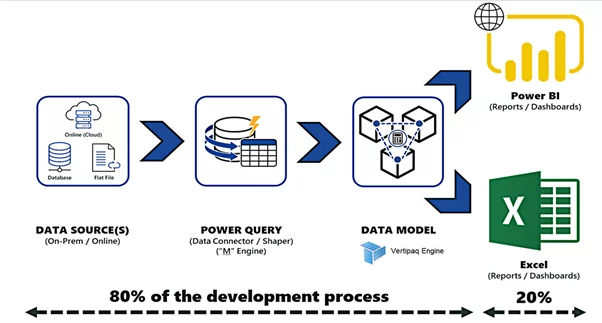
Power BI is a leading data analytics BI tool that has enabled data culture in multiple organizations. Power BI users can perform self-service BI, Enterprise BI analytics, and Big Data analytics all in a single Power BI Desktop and Power BI service. In a typical Power BI project, it takes 80% of development effort on data massaging, cleansing, and data modeling, and only takes 20% of effort on making visuals and artifacts.
We create Power Query (M Language) data extractor scripts to source data from the outer world. If we are using the import storage mode, then Power BI will move all the data into the Power BI data model using the Power queries. Once we have data in the Power BI data model, then the VERTIPAQ engine kicks in. Storing data in tabular cubes, performing I/O compression, applying filters, joining tables, and doing basic aggregations are the engine’s responsibilities. Behind the scenes, the Power BI data model creates the Analysis Services Tabular Cubes as a storage strategy. DAX language is used by the Vertipaq engine to slice and dice the available data on tabular cubes.
These are the steps for the PBI cube processing:
- Reading data from the source, transforming it into a columnar data structure of VertiPaq, encoding data available in each column.
- Indexing for each column.
- Creating Data structures for relationships.
- Computing the calculated columns
This engine makes Power BI the best Analytics platform when it comes to performance.
POWER BI AGG TABLES FOR BIG DATA ANALYTICS
Now I want to show you how Power BI aggregation features help us run analytics on big data sources.
Aggregations in Power BI helps us reduce table sizes so that we can focus on essential data and improve query performance. Aggregations enable swift and agile analysis over big data in ways that are not possible using traditional methods. It can, thereby, reduce the cost of exploring large datasets for decision making.
In Power BI, Aggregations start as tables just like any other table in a data model but with fewer rows than a detailed table.
Once in the model, these tables can be configured to answer queries by the engine.
To further explore how the aggregation tables can be used for big data analytics, the benefits of using these tables, and how to configure the aggregation, click here.
If you’ve any questions, feel free to reach out to us at [email protected] or visit our Business Intelligence Consulting page for more details.